数据库 Mybatis高级 FANSEA 2024-06-06 2025-05-03 Mybatis高级
【Java面试】八、MyBatis篇-CSDN博客
Spring整合Mybatis-Plus 版本选型:
Java:JKD17
Springboot:3.2.5
Mybatis-Plus:3.5.6
引入依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <scope > runtime</scope > <version > 5.1.47</version > </dependency > <dependency > <groupId > com.baomidou</groupId > <artifactId > mybatis-plus-spring-boot3-starter</artifactId > <version > 3.5.6</version > </dependency >
配置数据源
1 2 3 4 5 6 spring: datasource: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/demo?useSSL=false&serverTimezone=UTC username: root password: 123456
用MybatisX自动生成domain、mapper、service
添加mapper资源扫描路径
1 2 3 4 5 6 7 @SpringBootApplication @MapperScan("com.home.fansea.mapper") public class MiniXyIotApplication { public static void main (String[] args) { SpringApplication.run(MiniXyIotApplication.class, args); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <build > <resources > <resource > <directory > src/main/java</directory > <includes > <include > **/*.yml</include > <include > **/*.properties</include > <include > **/*.xml</include > <include > **/banner.txt</include > </includes > <filtering > false</filtering > </resource > <resource > <directory > src/main/resources</directory > <includes > <include > **/*.yml</include > <include > **/*.properties</include > <include > **/*.xml</include > <include > **/banner.txt</include > </includes > <filtering > false</filtering > </resource > </resources > </build >
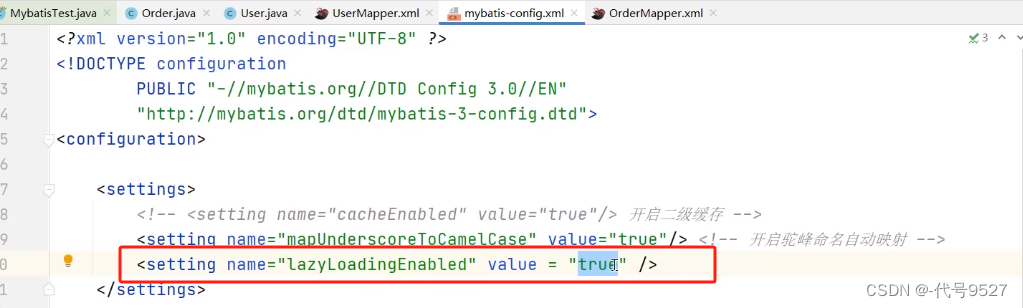
懒加载 
.png)
开启全局懒加载:
MyBatis延迟加载的原理:
使用动态代理,创建目标对象User的代理对象
调用user.getOrderList方法时,进入代理对象的intercept方法(或revoke方法)
intercept方法(或revoke方法),做判断,如果user.getOrderList是null值,就执行sql查询订单列表
查询完成后,调用user.setOrderList,封装订单信息到User的Order属性
正常调用真实对象中的方法的Method实例,即user.getOrderList
CGLIB代理是基于ASM(一个基于字节码操作的框架),通过修改字节码生成新类来对接口增强
.png)
数据库JSON格式与Java实体类映射实现
JSON格式建议用来对资源配置属性
1 2 @TableField(typeHandler = PgJsonTypeHandler.class) private Map<String, Object> settings;
编写处理类,继承实现BaseTypeHandler<Map<String, Object>>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 @Slf4j public class PgJsonTypeHandler extends BaseTypeHandler <Map<String, Object>> { private static final ObjectMapper objectMapper = new ObjectMapper (); public PgJsonTypeHandler () { super (); } @Override public void setNonNullParameter (PreparedStatement ps, int i, Map<String, Object> parameter, JdbcType jdbcType) throws SQLException { if (parameter != null ) { PGobject pgObject = new PGobject (); pgObject.setType("jsonb" ); try { String json = objectMapper.writeValueAsString(parameter); pgObject.setValue(json); ps.setObject(i, pgObject); } catch (Exception e) { throw new SQLException ("Error when converting Map to JSON string." , e); } } } @Override public Map<String, Object> getNullableResult (ResultSet rs, String columnName) throws SQLException { String json = rs.getString(columnName); return json == null ? null : parseJson(json); } @Override public Map<String, Object> getNullableResult (ResultSet rs, int columnIndex) throws SQLException { String json = rs.getString(columnIndex); return json == null ? null : parseJson(json); } @Override public Map<String, Object> getNullableResult (CallableStatement cs, int columnIndex) throws SQLException { String json = cs.getString(columnIndex); return json == null ? null : parseJson(json); } private Map<String, Object> parseJson (String json) throws SQLException { try { return objectMapper.readValue(json, new TypeReference <Map<String, Object>>() {}); } catch (Exception e) { log.error("Error parsing JSON: " + json, e); throw new SQLException ("Error parsing JSON string to Map. JSON: " + json, e); } } }
实际取用
1 project.getSettings().get("accessLevel" ).toString()
Mybatis缓存
一级缓存 对于一次会话的sqlSession开启的缓存,这个缓存通过一个Executor以及Local Cache实现
二级缓存
二级缓存则是一个全局的缓存,所有SqlSession共享,实现原理是对Executor进行装饰,让SqlSession先查询二级缓存,如果不命中再访问一级缓存,它的一个缓存粒度能精确到namespace(一个namespace对应一个Mapper),不同的SqlSession之间就可以共享一个mapper缓存。
开启二级缓存
配置 yaml文件
1 2 3 4 5 6 mybatis-plus: mapper-locations: classpath:mapper/*Mapper.xml configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl cache-enabled: true
在需要开启的 mapper.xml 中,添加以下代码(在下方)
1 2 <cache eviction ="FIFO" flushInterval ="60000" size ="512" readOnly ="false" />
eviction可用的清除策略有:
LRU – 最近最少使用:移除最长时间不被使用的对象。
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
默认的清除策略是 LRU。
flushInterval(刷新间隔)属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
size(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
写SQL的三种方式 mybatis中写sql的三种方式_mybatis生成sql-CSDN博客
配置xml
查看xml标签作用参考以下文章:
MyBatis中XML 映射文件中常见的标签_以下哪个不是mybatis映射文件中常见的标签-CSDN博客
1 2 3 4 5 public interface InviterMapper { Page<Inviter> getInviters (@Param("page") Page<Inviter> page, @Param("username") String username) ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace ="com.example.mapper.InviterMapper" > <resultMap id ="InviterResultMap" type ="com.example.model.Inviter" > <id column ="user_id" property ="userId" /> <result column ="tenant_id" property ="tenantId" /> <result column ="username" property ="username" /> <result column ="email" property ="email" /> <result column ="mobile" property ="mobile" /> <result column ="invitee_count" property ="inviteeCount" /> </resultMap > <select id ="getInviters" parameterType ="com.baomidou.mybatisplus.extension.plugins.pagination.Page" resultMap ="InviterResultMap" > SELECT pcc.create_by AS user_id, t.id AS tenant_id, u.name AS username, u.email AS email, u.mobile AS mobile, COUNT(pc.create_by) AS invitee_count FROM privilege_code_cdkey pcc INNER JOIN privilege_code pc ON pc.id = pcc.code_id RIGHT JOIN privilege_code_redeem pcr ON pcr.cdkey = pcc.cdkey INNER JOIN `user` u ON u.id = pcc.create_by INNER JOIN tenant t ON t.owner_id = u.id WHERE pc.type = 'invitation' <if test ="username != null and username != ''" > AND u.name = #{username} </if > GROUP BY pcc.create_by, u.name, u.email, u.mobile, t.id <if test ="page != null" > LIMIT #{page.offset}, #{page.limit} </if > </select > </mapper >
@Select 1 2 3 4 5 6 7 8 9 10 11 12 @Select(""" select t.id as id, t.organization_name as name, count(t.id) as count from tenant t left join user_tenant ut on t.id = ut.tenant_id and ut.is_deleted = 0 left join "user" u on u.id = ut.user_id and u.is_deleted = 0 where t.type = 'enterprise' and t.owner_id != u.id and ut.create_time between #{startDate} and #{endDate} and t.is_deleted = 0 group by t.id; """) List<InvitationCount> getInvitationCountList (@Param("startDate") Date startDate,@Param("endDate") Date endDate) ;
@SelectProvider 1 2 3 4 public interface UserMapper { @SelectProvider(type=SqlProvider.class,method="getUserById") List<User> AnnotationProviderGetUserById (String id) ; }
1 2 3 4 5 6 7 8 9 public class SqlProvider { public String getUserById (String id) { String sql = "select * from user " ; if (id!=null ) { sql += " where id=" +id; } return sql; } }
sql注入解释 :是一种代码注入技术,用于攻击数据驱动的应用,恶意的SQL语句被插入到执行的实体字段中
1 http://localhost:9211/association/user?username='jone' OR 1=1 //如果sql注入生效,将会把所有数据查出来
场景:
1 2 3 4 @GetMapping("/user") List<Users> getUser (@RequestParam("userName") String userName) { return usersMapper.selectByUserName(userName); }
1 2 3 <select id ="selectByUserName" resultType ="com.home.fansea.domain.Users" > select <include refid ="Base_Column_List" /> from users where userName = ${userName} </select >
结果:
拼接 or 1=1 语句成功的把所有user查了出来,在实际的开发中如果出现这种问题是十分严重的
mybatis中的#和$的区别:
#:将传入的信息都当做字符串来处理
$:将传入的数据直接显示生成在sql中,这样可能会导致SQL注入
#将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。
如:where username=#{username},如果传入的值是111,那么解析成sql时的值为where username=”111”, 如果传入的值是id,则解析成的sql为where username=”id”.
$将传入的数据直接显示生成在sql中。
如:where username=${username},如果传入的值是111,那么解析成sql时的值为where username=111;
如果传入的值是;drop table user;,则解析成的sql为:select id, username, password, role from user where username=;drop table user;
#方式能够很大程度防止sql注入,$方式无法防止Sql注入。
$方式一般用于传入数据库对象,例如传入表名.
一般能用#的就别用$,若不得不使用“${xxx}”这样的参数,要手工地做好过滤工作,来防止sql注入攻击。
在MyBatis中,“${xxx}”这样格式的参数会直接参与SQL编译,从而不能避免注入攻击。但涉及到动态表名和列名时,只能使用“${xxx}”这样的参数格式。所以,这样的参数需要我们在代码中手工进行处理来防止注入。
【结论】在编写MyBatis的映射语句时,尽量采用“#{xxx}”这样的格式。若不得不使用“${xxx}”这样的参数,要手工地做好过滤工作,来防止SQL注入攻击。
思考题 JPA
定义
JPA (Java Persistence API) 是 Java 平台的一个规范,用于管理关系型数据库中的数据。JPA 提供了一种标准的方法来映射 Java 对象到数据库表,并执行数据库操作,如保存、更新、删除和查询数据。它是通过使用注解或 XML 描述对象 - 关系元数据来实现这一点的。JPA 规范本身并不提供实现,而是由多个供应商提供具体的实现,例如 Hibernate、EclipseLink 和 OpenJPA。
定义的是规范,需要具体的实现,比如Hibernate
使用
引入依赖 :spring-boot-starter-data-jpa starter 来轻松地完成这一过程。
实体类定义 :@Entity 注解标记一个 Java 类为实体,同时使用 @Table 注解指定对应的数据库表名。例如:
1 2 3 4 5 6 7 8 9 10 11 12 @Entity @Table(name = "users") public class User { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(name = "username", nullable = false) private String username; }
持久化操作 :
保存实体 :使用 EntityManager 的 persist() 方法将新创建的实体保存到数据库。查询实体 :可以使用 EntityManager 的 find() 方法根据主键查找实体,或者编写 JPQL 查询来执行更复杂的搜索。更新实体 :通过修改已加载到内存中的实体对象的属性,然后调用 EntityManager 的 merge() 方法来更新数据库中的记录。删除实体 :使用 EntityManager 的 remove() 方法删除数据库中的记录。
配置数据源 :application.properties 或 application.yml 文件配置数据源连接信息,例如数据库 URL、用户名和密码等。
总结
JPA 为 Java 开发者提供了一个强大的工具,用于简化数据库操作。它不仅支持基本的 CRUD 操作,还支持事务管理、缓存机制以及高级查询等功能。通过 JPA,开发者可以更容易地实现数据持久化,而无需担心底层数据库的具体细节。在现代的 Java 应用开发中,尤其是使用 Spring Boot 进行的企业级应用开发中,JPA 是一个非常受欢迎的选择,因为它提供了良好的抽象和高度的灵活性。
JPA与Mybatis的区别?
都是对于ORM的持久化框架
JPA适合SQL简单的场景,是一种全自动的ORM持久化框架,而对于复杂查询需要更多配置
Mybatis适合复杂SQL场景,是一种半自动的ORM持久化框架,通过xml可以根据具体需求编写高效的 SQL 语句
常见问题 不良的类型值 long 1 java nested exception is org.postgresql.util.PSQLException: 不良的类型值 long
原因: Mybatis在结果集到对象的转换中出现了顺序问题
方案:
查看对象类是否只有未包含所有参数的构造方法
查看xml、类的顺序是否对应