手撕题
手撕题
FANSEA手撕题
单例模式
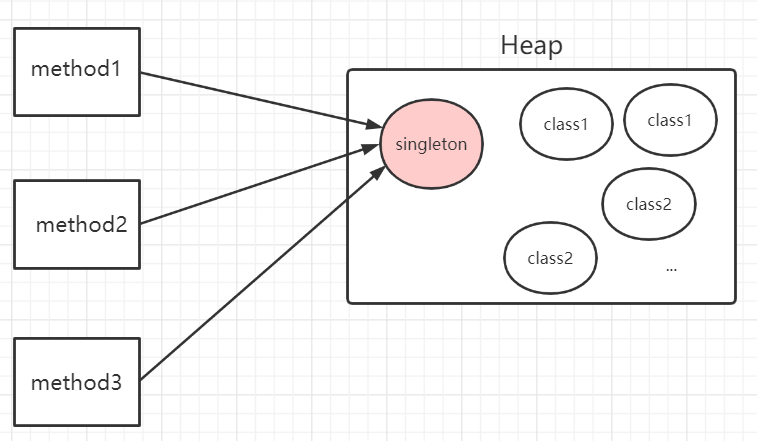
什么是单例模式
单例模式是指在内存中只会创建且仅创建一次对象的设计模式。在程序中多次使用同一个对象且作用相同时,为了防止频繁地创建对象使得内存飙升,单例模式可以让程序仅在内存中创建一个对象,让所有需要调用的地方都共享这一单例对象
1 | public class Singleton { |
Double Check(双重校验) + Lock(加锁)
- 使用volatile防止指令重排
创建一个对象,在JVM中会经过三步:
(1)为singleton分配内存空间
(2)初始化singleton对象
(3)将singleton指向分配好的内存空间(执行完这一步代表已经singleton不为空)
指令重排序是指:JVM在保证最终结果正确的情况下,可以不按照程序编码的顺序执行语句,尽可能提高程序的性能
在这三步中,第2、3步有可能会发生指令重排现象,创建对象的顺序变为1-3-2,会导致多个线程获取对象时,有可能线程A创建对象的过程中,执行了1、3步骤,线程B判断singleton已经不为空,获取到未初始化的singleton对象,就会报NPE异常。

队列
数组
入队O(1),出队O(n)
1 | public class Queue<T> { |
链表
入队O(1),出队O(1)
1 | public class LinkedQueue<T> { |
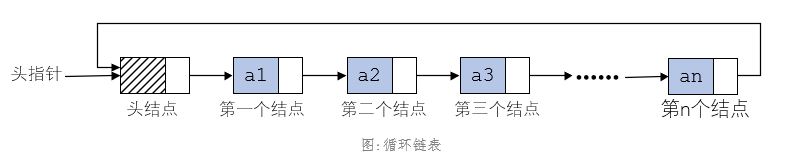
循环链表
- head
- tail
- size
https://blog.csdn.net/wkd_007/article/details/129824129
1 | public class LoopList<V> { |
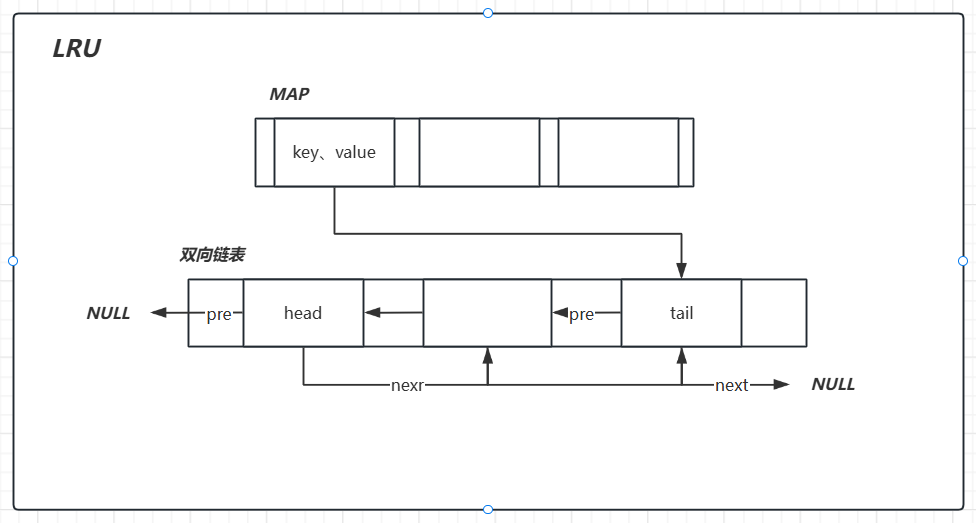
手写LRU
- capacity:缓存长度
- map:保障取数据的时间复杂度为
O(1) - head:对头节点变更频繁(
insert、get) - tail:长度超标时删除尾结点要用(
insert)
为什么要使用双向链表呢?
- 双向队列用于维护活跃的数据
- 当对一个元素进行更新操作时需要移动,移动需要对next以及pre进行连接,维护链表的线性结构,而单链表无法快捷找到pre的节点
1 | import java.util.HashMap; |
读写锁
1 | /** |
自定义线程池
确定参数:
- 核心线程数
- 最大线程数
- 是否关闭
- 阻塞队列
- 最大活跃时间(单位)
- 工作线程数量
submit()方法:
- 小于最大线程:加入任务
- 大于最大线程:加入队列、拒绝任务
Work工作类:
循环
- 如果有任务直接执行
- 没有任务阻塞获取任务,如果超时判断是否工作线程大于核心线程,超过则释放当前线程
1 | public class ThreadPool { |
螺旋矩阵
- 定义上下左右四个指针
- 通过固定一个指针,操作另外一个指针达到螺旋效果(→↓←↑)
- 缩小所有指针一个单元的范围
1 | private static int[][] spiralMatrix(int n){ |
排序
归并排序

1 | private static int[] mergeSort(int[] arr,int l,int r){ |
快速排序
对整个数组进行排序,大于基准元素的在右边,小于的在左边,然后再对基准元素左右两边的数组递归排序
i:小于基准元素的空缺位指针j:大于基准元素的空缺位指针
1 | private static void quickSort(int[] arr, int i, int j) { |
递归
反转链表
1 | public ListNode ReverseList (ListNode head) { |
二叉树中 2 个节点的最先公共祖先
二叉树(反)序列化
序列化
1 | public String serialize(TreeNode root) { |
反序列化
1 |
字符串
反转字符串II
1 | public String reverseStr(String s, int k) { |
大数相加
1 | int al = a.length()-1; |
树
前序遍历
1 | public static void preOrder(TreeNode n){ |
中序遍历
1 | public static void midOrderPlus(TreeNode n){ |
有序数组转化为平衡二叉树
二叉搜索树
- 非空左子树的所有键值小于其根结点的键值。
- 非空右子树的所有键值大于其根结点的键值。
- 左、右子树都是二叉搜索树。
1 | public TreeNode sort(int[] arr,int l,int r){ |
常用API
String
toCharArray()
indexOf(int ch) 和 lastIndexOf(int ch) - 返回指定字符在此字符串中第一次出现或最后一次出现处的索引。
1
2int indexFirst = str.indexOf('l'); // 2
int indexLast = str.lastIndexOf('l'); // 3substring(int beginIndex) 和 substring(int beginIndex, int endIndex) - 返回一个新的字符串,它是此字符串的子串。
1
2String subStr = str.substring(1); // "ello"
String subStrRange = str.substring(1, 4); // "ell"replace(char oldChar, char newChar) - 返回一个新的字符串,它是通过用新字符替换此字符串中出现的所有旧字符生成的。
1
String replacedStr = str.replace('l', 'p'); // "Heppo"
toLowerCase() 和 toUpperCase() - 将所有字符转换为小写或大写。
1
2String lowerCaseStr = str.toLowerCase(); // "hello"
String upperCaseStr = str.toUpperCase(); // "HELLO"trim() - 返回一个去除首尾空格的新字符串。
1
2String withSpaces = " Hello ";
String trimmed = withSpaces.trim(); // "Hello"split(String regex) - 根据给定的正则表达式拆分此字符串。
1
String[] words = "Hello World".split(" "); // ["Hello", "World"]
这些方法能够帮助你高效地处理字符串数据,无论是进行简单的字符串操作还是复杂的文本处理任务。根据具体需求选择合适的方法使用。
Map
在Java中,Map 接口和其实现类(如 HashMap, TreeMap, LinkedHashMap 等)提供了一种存储键值对的方式。以下是一些常用的 Map API 方法:
remove(Object key) - 如果存在一个键的映射关系,则将其从此映射中移除。
1
map.remove("Apple");
containsKey(Object key) - 如果此映射包含指定键的映射关系,则返回
true。1
boolean hasApple = map.containsKey("Apple");
containsValue(Object value) - 如果此映射将一个或多个键映射到指定值,则返回
true。1
boolean hasValue = map.containsValue(1);
keySet() - 返回此映射中包含的键的
Set视图。1
Set<String> keys = map.keySet();
values() - 返回此映射中包含的值的
Collection视图。1
Collection<Integer> values = map.values();
entrySet() - 返回此映射中包含的映射关系的
Set视图。1
2
3
4Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}isEmpty() - 如果此映射未包含键-值映射关系,则返回
true。1
boolean empty = map.isEmpty();
clear() - 从此映射中移除所有映射关系。
1
map.clear();
size() - 返回此映射中的键-值映射关系数。
1
int size = map.size();
putAll(Map<? extends K, ? extends V> m) - 从指定映射中将所有映射关系复制到此映射中。
1
2
3Map<String, Integer> anotherMap = new HashMap<>();
anotherMap.put("Banana", 2);
map.putAll(anotherMap);
这些方法提供了强大的功能来管理键值对集合,适用于各种场景,比如数据缓存、配置信息存储等。选择合适的实现类(如 HashMap 提供快速查找但不保证顺序,而 LinkedHashMap 保持插入顺序,TreeMap 按键排序)可以进一步满足特定需求。
数组
构造器:
1 | new String(arr) // 直接将数组转化为字符串 |
Arrays
在Java中,Arrays 类提供了一系列静态方法用于操作数组,如排序、搜索、比较等。以下是一些常用的 Arrays 方法:
sort() - 对数组进行排序。
1
2int[] numbers = {3, 1, 2};
Arrays.sort(numbers); // 排序后,numbers 数组变为 [1, 2, 3]binarySearch() - 使用二分查找算法查找指定元素的索引。注意,使用此方法前需要对数组进行排序。
1
int index = Arrays.binarySearch(numbers, 2); // 查找值为2的元素的位置
equals() - 比较两个数组是否相等(元素数量和内容相同)。
1
boolean isEqual = Arrays.equals(array1, array2);
toString() - 将数组转换为字符串表示形式。
1
String str = Arrays.toString(numbers); // 输出 "[1, 2, 3]"
asList() - 将数组转为
List。1
List<String> list = Arrays.asList(new String[]{"a", "b", "c"});
fill() - 用特定值填充数组。
1
Arrays.fill(numbers, 5); // 将 numbers 数组中的所有元素设置为 5
copyOf() 和 copyOfRange() - 复制数组或数组的一部分。
1
2int[] newArray = Arrays.copyOf(numbers, 5); // 复制长度为5的新数组
int[] rangeArray = Arrays.copyOfRange(numbers, 1, 3); // 复制从索引1到3(不包括3)的元素
这些方法可以大大简化数组的操作过程,使得代码更加简洁高效。请根据实际需求选择合适的方法使用。
SQL加油站
前置SQL
1 | create table Student(sid varchar(10),sname varchar(10),sage datetime,ssex nvarchar(10)); |
- 查询“01”课程比“02”课程成绩高的所有学生的学号?
1 | SELECT t1.sid FROM (SELECT * FROM sc WHERE sc.cid = '01') t1 |
- 查询平均成绩大于60分的同学的学号和平均成绩;
1 | select sid,AVG(score) FROM sc GROUP BY sid HAVING AVG(score)>60 |
- 查询所有同学的学号、姓名、选课数、总成绩
请注意:使用
GROUP BY分组函数检索的非聚合函数属性都必须在GROUP BY条件之后!
1 | SELECT |
- 查询姓“李”的老师的个数;
1 | select count(t.tid) from teacher t where t.tname like '李%'; |
- 查询没学过“张三”老师课的同学的学号、姓名;
1 | select |





