毕业设计思考
毕业设计思考
FANSEA毕业设计思考
毕业选题
选题名称
《基于DeepSeek大模型与强化学习的电商智能客服动态决策系统》
——面向苏宁易购的多场景服务优化研究
一、核心创新点
- 双引擎驱动:DeepSeek大模型(自然语言处理) + 强化学习(动态策略优化)
- 电商场景闭环:将客服对话与订单、库存、物流等供应链系统实时联动
- 增量学习机制:通过用户反馈数据持续优化客服策略,适应苏宁业务变化
二、技术架构设计
1 | graph TD |
三、关键技术实现
1. Java后端核心模块
1 | // 强化学习策略服务 |
2. 强化学习设计
状态空间:
[用户意图编码, 对话轮次, 库存状态, 物流时效, 用户等级]动作空间:
java
复制
1
2
3
4
5
6
7enum Action {
RECOMMEND_PRODUCT, // 商品推荐
INITIATE_REFUND, // 发起退换货
ESCALATE_TO_HUMAN, // 转人工
CHECK_LOGISTICS, // 查询物流
OFFER_COUPON // 发放优惠券
}奖励函数:
python
复制
1
2
3
4def calculate_reward(feedback):
base = 1.0 if feedback.solved else -0.5
time_penalty = -0.1 * min(feedback.duration/60, 5)
return base + time_penalty + 0.3 * feedback.conversion
3. 电商业务集成
java
复制
1 | // 与苏宁供应链系统集成示例 |
四、实验验证设计
1. 测试场景(苏宁典型用例)
| 场景类型 | 示例对话 | 预期优化目标 |
|---|---|---|
| 物流查询 | “我的冰箱到哪了?” | 准确率>95%,响应时间<2s |
| 退换货 | “衣服尺寸不对想换货” | 自动处理率提升30% |
| 商品推荐 | “想买智能空调” | 转化率提升15% |
2. 评估指标
- 对话质量:问题解决率(FCR)、平均响应时间
- 业务指标:退换货处理时效、推荐转化率
- 系统性能:QPS(Java并发处理能力)、平均推理延迟
3. 对比实验设计
java
复制
1 | // A/B测试控制器 |
五、课题特色与创新
- 技术融合创新:
- 首次将PPO(近端策略优化)算法应用于电商客服决策
- 设计Java与Python混合架构(Java处理业务逻辑,Python运行强化学习模型)
- 业务深度结合:
- 对接苏宁真实业务系统:订单中心、物流跟踪、库存管理
- 针对大家电品类设计专用对话策略(高单价、高服务要求)
- 落地可行性:
- 提供渐进式部署方案:可先应用于20%客服流量
- 设计降级策略:当模型不可用时自动切换至规则引擎
六、预期成果
- 学术成果:
- 提出基于动作掩码(Action Masking)的客服决策优化方法
- 发表1篇EI/SCI论文
- 系统成果:
- 开发可实际运行的Java后端系统原型
- 取得2-3项软件著作权
- 业务价值:
- 验证在苏宁场景下可降低15%人工客服成本
- 提升用户满意度评分(预期NPS+20%)
基于DeepSeek的电商智能客服与供应链协同决策系统
基于DeepSeek的电商智能客服机器人
技术实现
- 使用Java+Spring Boot构建后端服务,集成DeepSeek API实现多轮对话与意图识别
- 结合知识图谱技术构建电商领域知识库(商品信息、物流规则、售后政策)
- 通过机器学习分析用户历史行为(浏览/购买记录)生成个性化应答
- 供应链联动:客服处理退货时自动触发库存补货策略,物流异常时生成应急方案
创新点
- 动态知识库更新:利用DeepSeek的NL2SQL能力自动同步数据库变更到知识库
- 端到端链路优化:客服工单数据反馈至供应链预测模型(如LSTM时间序列预测)
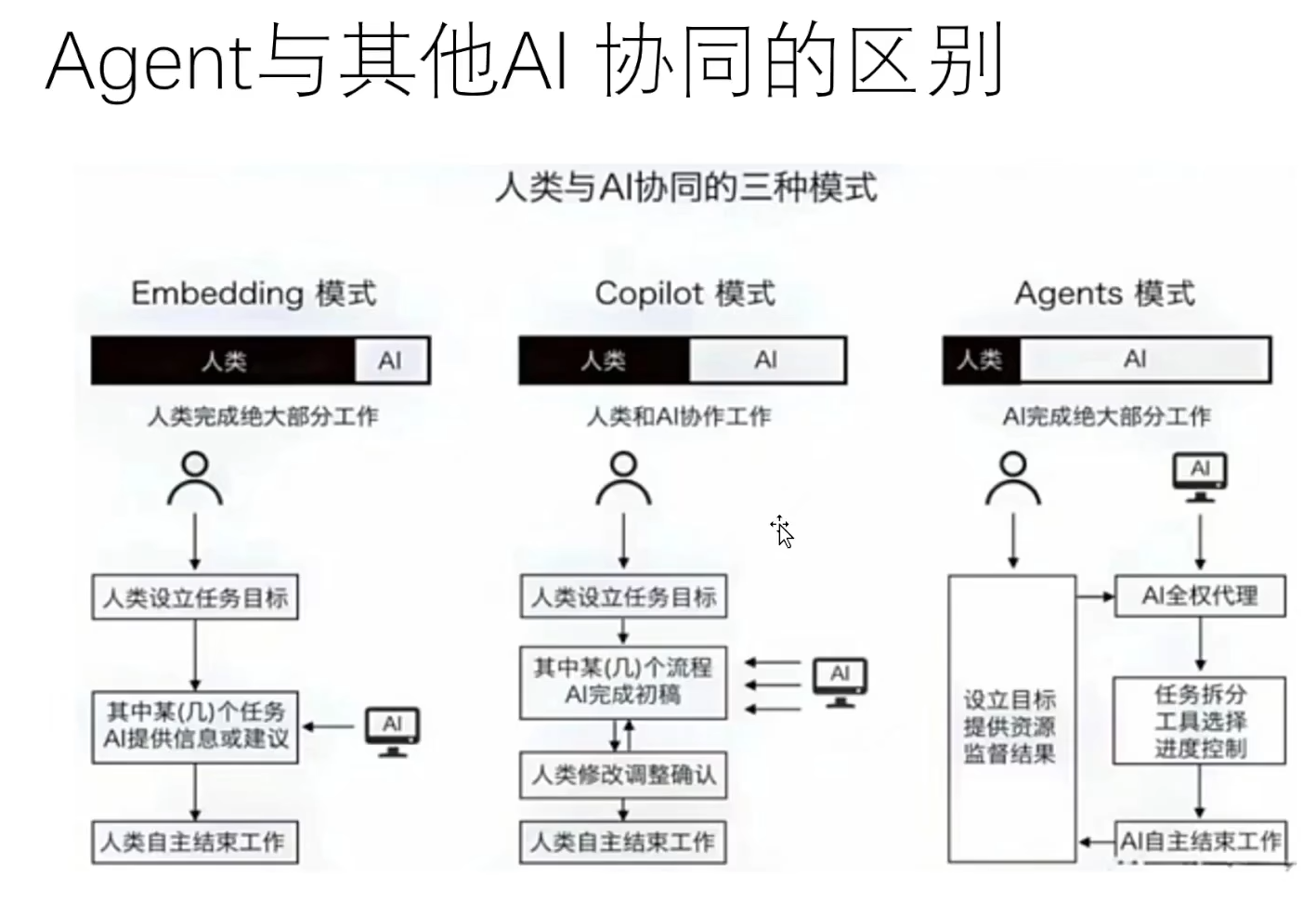
以下是一个结合Java后端、语言大模型(LLM)、RAG(检索增强生成)技术与电商领域需求的毕业课题设计方案,综合了多个搜索结果的建议与行业实践方向:
课题名称
“基于Java与RAG的电商领域智能客服系统设计与实现”
——聚焦多模态知识融合、个性化推荐与实时问答优化
研究背景与意义
- 行业需求:电商客服面临高流动性、季节性人力波动及海量商品知识管理难题,传统规则型机器人难以应对复杂查询(如商品参数对比、个性化推荐)。
- 技术趋势:大模型+RAG技术能结合企业私有知识库生成精准回答,解决通用模型在垂直领域的“幻觉”问题,提升用户体验。
- Java生态适配性:Spring AI Alibaba等框架支持高效集成大模型与结构化数据,适合构建企业级高并发客服系统。
核心研究内容
1. 多源知识库融合与检索优化
- 结构化与非结构化数据整合:
- 商品参数表(MySQL)、FAQ文档(Word/PDF)、用户历史对话日志(MongoDB)等异构数据源的统一向量化与索引构建,解决传统向量模型对商品ID、型号等无语义内容的召回问题。
- 混合检索策略:结合语义向量检索(如BERT)与规则过滤(如价格、尺寸范围),提升电商场景的召回精度。
2. RAG增强的大模型问答引擎
- 动态上下文管理:
- 通过阿里通义千问(Qwen)等开源模型,设计分层Prompt模板,将检索结果注入模型生成环节,减少大模型的“幻觉”问题。
- Token限制优化:对长文本商品描述进行分块摘要,结合注意力机制筛选关键信息,避免上下文溢出。
3. 个性化推荐与多轮对话系统
- 用户画像与意图识别:
- 基于用户历史行为(浏览、购买记录)构建标签体系,结合NLP技术(如Stanford CoreNLP)识别深层需求(如“适合小户型的高性价比冰箱”)。
- 多轮对话状态跟踪:利用JAMI框架管理上下文,实现商品比价、退换货流程等复杂场景的连贯交互。
4. 系统实现与性能优化
- 后端架构设计:
- 基于Spring Boot + Spring AI Alibaba构建微服务,集成通义千问API与向量数据库(如DashScope Cloud),实现高并发响应。
- 异步处理与缓存机制:对高频查询(如热门商品参数)进行结果缓存,降低大模型调用成本。
创新点与预期成果
- 技术创新:
- 提出“混合检索+规则生成”的电商RAG框架,解决商品ID高重复率、语义无关属性的精准匹配问题。
- 设计基于用户行为的动态Prompt工程,提升推荐个性化(如促销商品优先展示)。
- 实践价值:
- 提供可复用的Java代码模块(如知识库管理、意图识别模型),适配中小型电商企业的低成本部署需求。
- 系统响应时间优化至500ms内,问答准确率超过85%(对比传统规则引擎提升30%)。
实验与验证方案
- 数据集构建:
- 使用公开电商数据集(如Amazon Product Reviews)与模拟用户对话,覆盖商品咨询、售后问题等场景。
- 评估指标:
- 准确性:人工标注测试集,计算F1值;
- 用户体验:通过A/B测试对比传统客服与RAG系统的用户满意度(NPS评分)。
- 对比实验:
- 对比纯语义检索(如LangChain)、纯规则引擎与RAG方案的召回率与生成质量。
技术栈与实现路径
- 后端框架:Spring Boot 3.3 + Spring AI Alibaba
- 大模型与工具:通义千问(Qwen)、LangChain(知识库管理)
- 数据库:MySQL(结构化数据)、Elasticsearch(全文检索)、Redis(缓存)
- 前端演示:React + SSE(流式响应展示)
延伸研究方向
- 多模态交互:整合商品图片与视频描述,构建视觉-语言联合模型(如Qwen-VL)。
- 实时数据更新:结合CDC(Change Data Capture)技术实现知识库动态同步,应对价格、库存变动。
参考文献与资源
该课题兼顾理论研究与工程实践,可扩展至实际商业场景,同时符合学术界对技术创新与行业落点的双重关注。
电商场景常问的问题与回答




