技术漫谈
技术漫谈
FANSEA技术漫谈
如何解决订单一致性问题
Lua + RocketMq事务消息
- Lua:保障原子性,相比Java事务响应更加快捷
- RocketMq:保障消息发送环节的事务性
XA协议
- 原理:将四个调用分支封装成包含四个独立事务分支的大事务
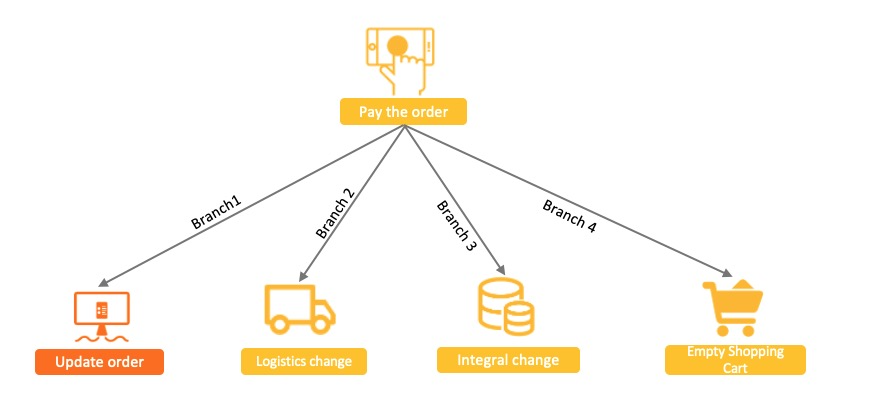
- 特点:多分支环境下资源锁定范围大,并发度低,随着下游分支的增加,系统性能会越来越差
普通消息+订单事务
- 原理:基于MQ异步实现事务同步
- 特点:并发量大、无法保证最终一致性
该方案中消息下游分支和订单系统变更的主分支很容易出现不一致的现象,例如:
- 消息发送成功,订单没有执行成功,需要回滚整个事务。
- 订单执行成功,消息没有发送成功,需要额外补偿才能发现不一致。
- 消息发送超时未知,此时无法判断需要回滚订单还是提交订单变更。
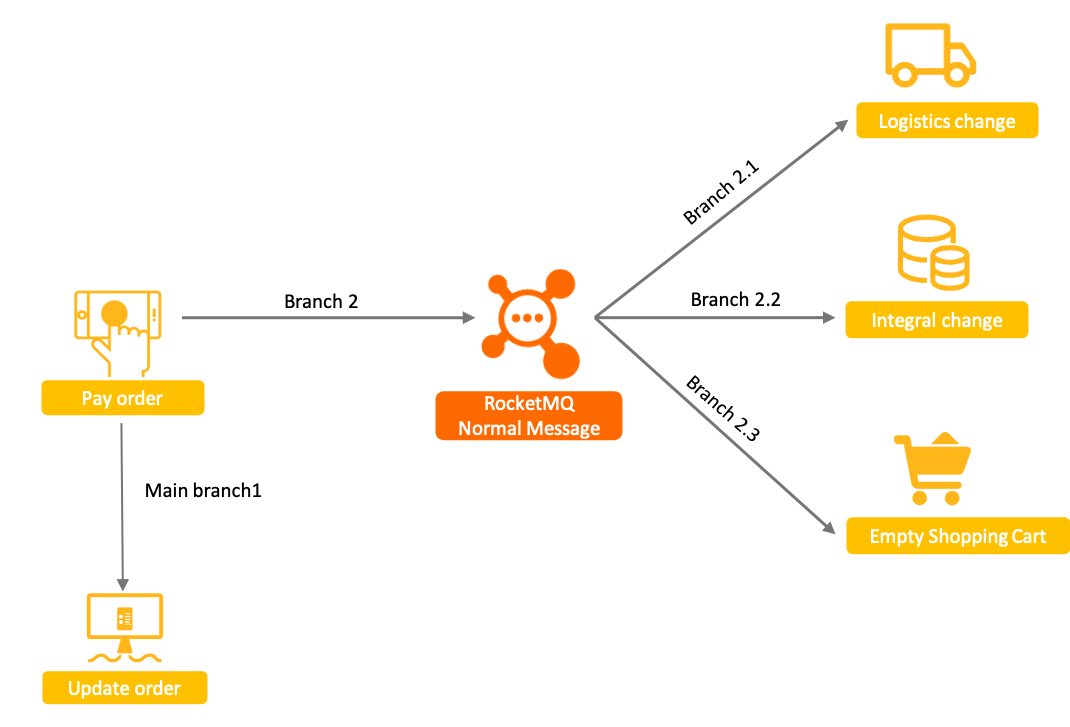
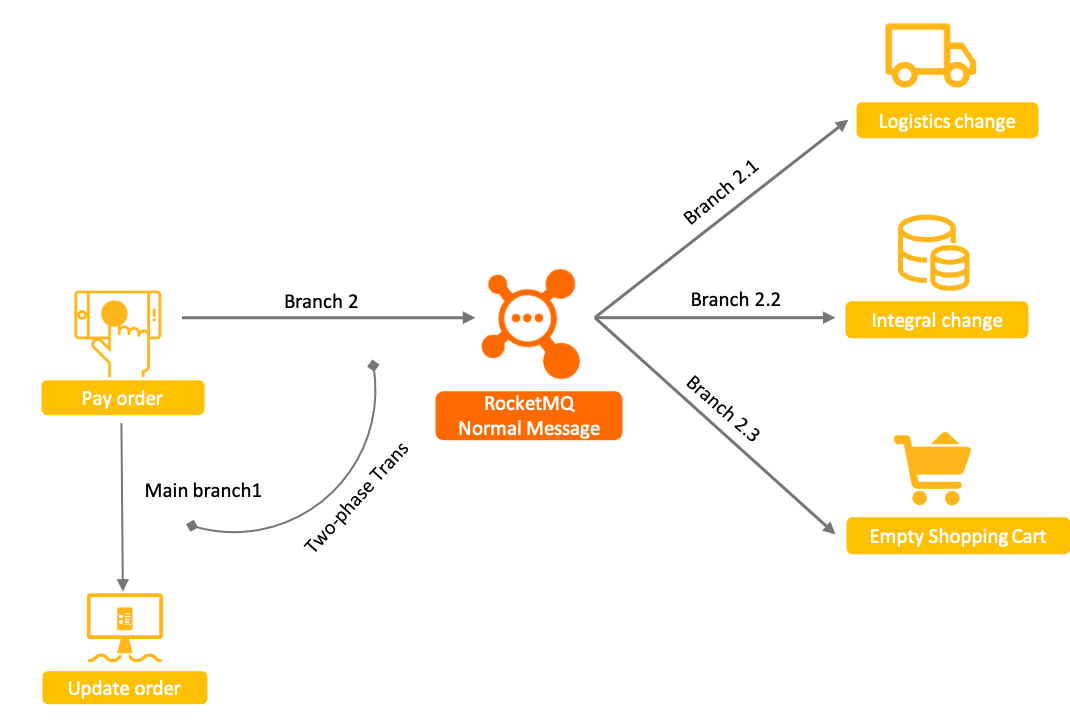
RocketMQ事务消息
用于分布式服务间的最终一致性,将消息发送和主事务绑定,解决了普通消息+主事务的结果不一致的问题
上述普通消息方案中,普通消息和订单事务无法保证一致的原因,本质上是由于普通消息无法像单机数据库事务一样,具备提交、回滚和统一协调的能力。
而基于Apache RocketMQ实现的分布式事务消息功能,在普通消息基础上,支持二阶段的提交能力。将二阶段提交和本地事务绑定,实现全局提交结果的一致性。
- 原理:普通消息+订单事务的基础上对消息发送这个步骤增加事务(事务消息具备提交、回滚和统一协调的能力)
- 特点:保证并发的同时、并且保证最终一致性
使用实例
Apache RocketMQ 是一款分布式消息中间件,它支持多种消息模式,包括事务消息。事务消息主要用于确保本地事务和消息发送的一致性。下面是一个使用 Java 实现 RocketMQ 事务消息的基本示例。
首先,你需要确保你的环境中已经安装了 RocketMQ 的 Broker 和 NameServer,并且正确配置了环境。
步骤 1: 创建事务生产者
首先,你需要创建一个 TransactionProducer 实例,并设置一个 executeLocalTransactionBranch 方法来处理本地事务。
1 | import org.apache.rocketmq.client.producer.DefaultMQProducer; |
步骤 2: 处理事务状态检查
RocketMQ 的 Broker 会异步地回调 checkLocalTransactionState 方法来确认消息的状态。如果本地事务状态未知,Broker 将会调用这个方法来确认消息是否应该提交还是回滚。
1 |
|
请注意,上述示例代码仅为示意性的,实际使用时需要根据具体的业务逻辑实现 executeLocalTransactionBranch 和 checkLocalTransactionState 方法。此外,还需要确保 TransactionMQProducer 的启动和关闭逻辑正确处理。
在实际部署时,请替换 localhost:9876 为你的 NameServer 地址,并确保 TransactionProducerGroup 名称唯一且符合你的命名规则。
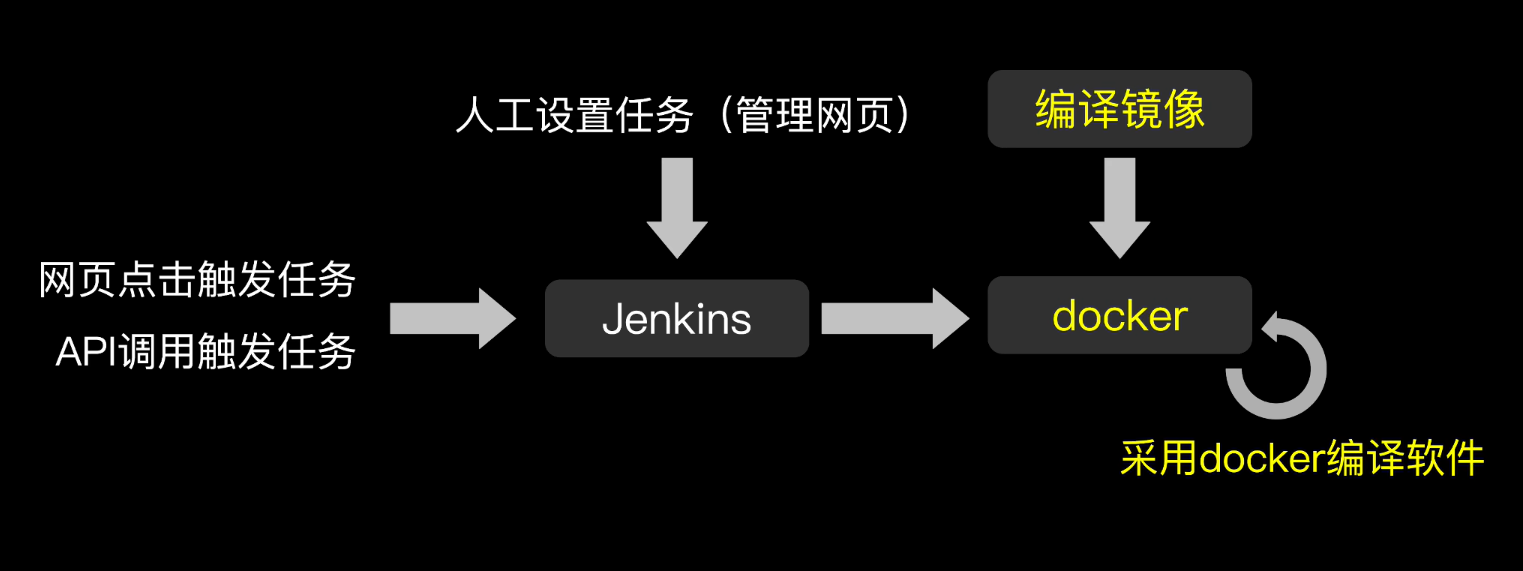
Jenkins
- 自动CI/CD
- 集成多插件满足多种编译需求
- 支持Git,远程在服务器部署程序
- 配合Docker实现快速编译
- 定义任务-远程启动-分布式
实时数据更新
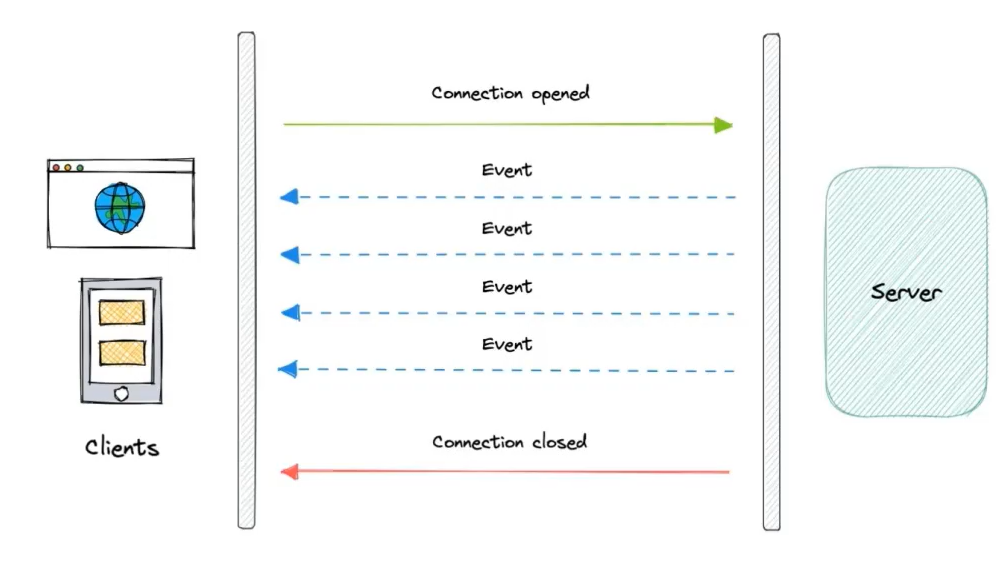
SSE
Server-Send Event
特点:
- 只支持单向通信
- 不能发送二进制数据、只能发送UTF-8的数据
短轮询
不断轮询服务器来获取最新数据
长轮询
一个HTTP请求打到服务器
- 如果数据没有更新,连接会被挂起(Hang住),等待30s如果更新了就返回更新数据
- 如果数据更新了就直接返回
用途:消息实时性要求高、数据更新频率不快
WebSocket
特点:
- 实时性: 由于WebSocket的持久化连接,它可以实现实时的数据传输,避免了Web应用程序需要不断地发送请求以获取最新数据的情况。
- 双向通信: WebSocket协议支持双向通信,这意味着服务器可以主动向客户端发送数据,而不需要客户端发送请求。
- 减少网络负载: 由于WebSocket的持久化连接,它可以减少HTTP请求的数量,从而减少了网络负载。
使用场景:
在线聊天
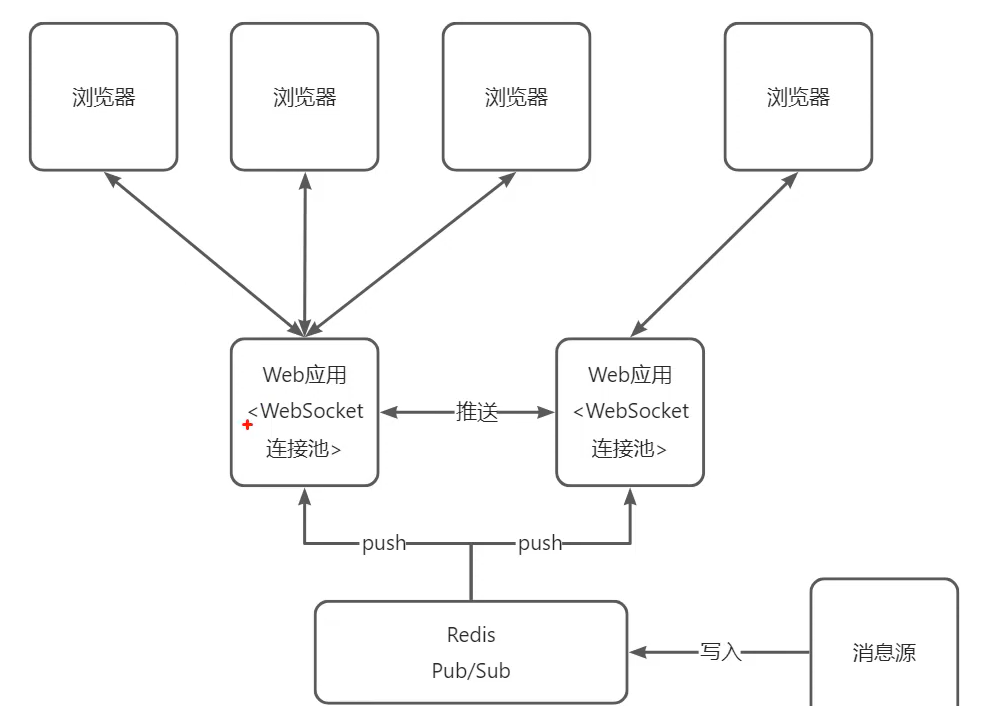
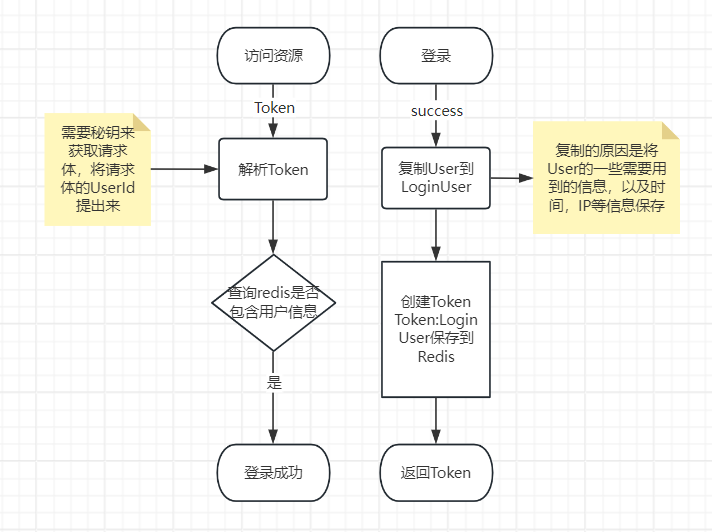
JWT登录
JWT(JSON Web Token)定义
JWT是一种用于在网络应用间安全地传输信息的标准(RFC 7519)。它是一种轻量级的开放标准,用于在各方之间以安全的方式传输信息。JWT通常用于身份验证和服务之间传递授权信息。JWT由三部分组成:头部(Header)、负载(Payload)以及签名(Signature),这三部分通过点号(.)连接。
JWT的优点
- 无状态:JWT包含所有用户认证信息,因此不需要存储在服务器端,使得其成为无状态的,可以跨域使用。
- 紧凑性:JWT是紧凑且自包含的,使得它可以通过URL、POST参数或者在HTTP header中轻松传送。
- 缓存友好:因为JWT是无状态的,所以可以被浏览器缓存,而不会带来任何安全隐患。
- 支持多种加密算法:JWT支持HMAC算法或RSA公私钥对进行签名。
- 易于扩展:可以在JWT中加入任何可序列化为JSON的信息。
JWT的结构原理
JWT由以下三部分组成:
Header(头部):
头部通常包含了令牌的类型和所使用的签名算法。例如:1
{"typ":"JWT","alg":"HS256"}
Payload(负载):
负载包含了需要传递的信息。这部分是JWT的核心,也是应用程序想要声明的所有相关信息所在的地方。例如:1
{"sub":"1234567890","name":"John Doe","iat":1516239022}
sub表示主体,通常是用户ID。name表示用户的名字。iat是签发时间,UNIX时间戳格式。
Signature(签名):
因为签名的创建是经过负载的,所以在负载内容被篡改时,这会在解析Token时发现签名一定会和负载不对应,导致Token失效
签名用于验证消息发送者的真实性,并且确保消息没有被篡改。它是通过指定的算法(如 HMAC SHA256)结合Header、Payload以及一个密钥(Secret)计算出来的字符串。例如:
1
2
3
4HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret)
整个JWT就是将这三部分用.连接起来的一个字符串。例如:
1 | eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c |
这个字符串分为三个部分:头部、负载、签名。
创建:
1 | public class CreateToken { |
解析:
1 | public class AnalysisToken { |
代码实现
- 创建令牌
1 | public String createToken(LoginUser loginUser) |
- 解析令牌
1 | public LoginUser getLoginUser(HttpServletRequest request) |
程序设计六大设计原则
在软件工程中,有多个设计原则用于指导开发者编写可维护、可扩展、健壮的代码。虽然不同文献和实践者可能会有所差异,但通常提到的“六大设计原则”指的是面向对象设计的SOLID原则。这些原则有助于避免代码僵化、脆弱、难以理解等问题,使软件系统更加灵活、易于维护和扩展。
程序设计的六大原则必要性:一者在团队协作下编写可读性代码尤为重要,二来方便代码扩展
以下是SOLID原则的具体内容:
单一职责原则(Single Responsibility Principle, SRP)
- 每个类应该只有一个改变的理由。这意味着一个类应该只负责一项功能,这样当需求变化时,只需修改一个类即可。
开放封闭原则(Open/Closed Principle, OCP)
- 软件实体(类、模块、函数等)应该是可扩展的,但不可修改的。也就是说,可以通过添加新的代码来扩展一个模块的功能,而不应当修改已有的代码。
里氏替换原则(Liskov Substitution Principle, LSP)
- 子类必须能够替换掉它们的基类。简单来说,就是任何可以使用父类的地方,也应该能够使用子类而不会导致错误。
接口隔离原则(Interface Segregation Principle, ISP)
- 使用者不应该被强迫依赖于它们不使用的方法。也就是说,应该将接口设计得足够具体,使得实现类不需要实现不相关的功能。
依赖倒置原则(Dependency Inversion Principle, DIP)
- 高层模块不应该依赖于低层模块,二者都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
依赖于抽象,便于未来扩展新功能
迪米特法则(Law of Demeter, LoD)
- 有时也被认为是一个设计原则,它指出一个对象应该对其它对象有最少的了解。即一个对象应当对其它对象有尽可能少的引用,这样可以降低对象之间的耦合度。
依赖倒置原则
依赖倒置原则(Dependency Inversion Principle, DIP)强调高层模块不应该依赖于低层模块,二者都应该依赖于抽象;抽象不应该依赖于细节,细节应该依赖于抽象。通俗地说,就是鼓励我们通过接口或抽象类来编程,而不是针对具体的实现类编程。
为了更好地理解依赖倒置原则,让我们来看一个简单的例子:
示例背景
假设我们需要开发一个系统,其中包括一个用户界面(UI)和一个数据处理逻辑。用户界面需要显示一些数据,而数据处理逻辑负责获取数据并进行处理。
传统方式
传统的方式可能是这样的:
1 | public class DataFetcher { |
在这个例子中,UI 类直接依赖于 DataFetcher 类。这种方式的问题是,如果 DataFetcher 发生了变化,那么 UI 也需要随之改变。此外,如果我们想要测试 UI 类,就必须有一个实际的 DataFetcher 实例,这增加了测试的难度。
应用依赖倒置原则
现在,我们应用依赖倒置原则,将具体的实现转为依赖抽象:
- 定义一个接口或抽象类,表示数据获取的行为。
- 高层模块(UI)依赖这个接口,而不是具体的实现。
- 低层模块(DataFetcher)实现这个接口。
下面是改进后的代码示例:
1 | // 定义一个数据获取行为的接口 |
在这个例子中,UI 类依赖于 IDataFetcher 接口,而具体的实现类如 NetworkDataFetcher 或 FileDataFetcher 则实现了这个接口。这种设计的好处是:
UI类不关心具体的数据来源,只需要知道如何获取数据。- 如果需要更改数据源,只需要更换
IDataFetcher的实现类。 - 测试变得更加容易,可以通过构造函数传递一个模拟的
IDataFetcher实现来进行单元测试。
通过这个例子可以看出,依赖倒置原则通过依赖抽象,减少了各个组件间的耦合性,提高了系统的灵活性和可测试性。
接口隔离原则
接口隔离原则(Interface Segregation Principle, ISP)提倡的是不应该强迫类去实现它们不需要的方法。换句话说,一个类不应该被迫实现它不会使用的所有接口方法。ISP 主张将胖接口拆分成更细粒度的接口,以便实现类只需要实现它们真正关心的部分。
下面通过一个简单的 Java 示例来说明接口隔离原则的重要性及其应用。
示例背景
假设我们正在开发一个游戏系统,其中包含动物(Animal)和飞行器(Vehicle)两种类型的对象。每种对象都有它们独特的功能。
问题描述
在没有应用 ISP 的情况下,我们可能会有这样的设计:
1 | interface IMoveable { |
在这个设计中,Animal 类并不支持飞行和游泳,但是由于 IMoveable 接口中定义了这些方法,所以 Animal 类必须实现它们。即使 Animal 类在实现这些方法时仅仅打印出不支持的消息,这也违反了 ISP 的精神。
应用 ISP 的解决方案
按照 ISP 的原则,我们应该将接口拆分为更具体的接口,让类只实现它们实际需要的方法:
1 | interface IMovable { |
在这个改进的设计中:
Animal类只需要实现IMovable接口。FlyingVehicle类实现了IMovable和IFlyable接口。SwimmingVehicle类实现了IMovable和ISwimmable接口。
这样,每种类型的对象都只实现了它们实际需要的方法,从而避免了不必要的方法实现,提高了代码的清晰度和可维护性。
迪米特法则
一个类方法调用另外一个类的逻辑,应该对其他实体有最少的了解,这样可以减少耦合性
迪米特法则(Law of Demeter, LoD),又称为最少知识原则(Least Knowledge Principle, LKP),主张一个软件实体(如类、模块、函数等)应该对其他实体有最少的了解。这意味着一个对象应该尽可能减少与其他对象的交互,仅与它的‘朋友’通信。‘朋友’一般是指当前对象的成员变量、参数、返回的对象等。
应用迪米特法则可以减少对象之间的耦合度,提高系统的灵活性和可维护性。
示例背景
假设我们有一个学校管理系统,需要处理学生、课程和成绩的关系。具体来说,我们需要一个功能来计算学生的总成绩。
违反迪米特法则的示例
首先,我们看看违反迪米特法则的情况:
1 | public class Student { |
在这个例子中,Student 类直接访问了 Course 类的内部状态 grades,并且还调用了 Grade 类的方法 getScore()。这样做的问题是 Student 类与 Course 类和 Grade 类耦合得太紧,不利于系统的扩展和维护。
应用迪米特法则的示例
接下来,我们来看看如何通过迪米特法则来优化上述设计:
1 | public class Student { |
在这个改进的设计中:
Student类不再直接访问Course类的内部状态grades。Student类通过调用Course类的calculateScores()方法来获得总分数。Course类封装了与其内部Grades的交互逻辑。
通过这种方式,Student 类仅需知道 Course 类提供的公共方法,而不需要了解其内部结构,这就降低了 Student 类与 Course 类之间的耦合度。
保障缓存和数据库一致性
执行数据更新操作时,就会出现缓存和数据库的一致性问题
方法一:延迟双删
更新时先把缓存删除,并在数据保存在数据库后延时一点时间再把缓存删除,保障最终一致性
第一次删除保障更新完数据后,这个时候的访问能拿到最新数据,缓存到Redis,而不至于访问到旧的数据,虽然最后这个存在的Redis的Key最后会被延时删除,但是确实保障了这更新期间的一致性
如果没有后面这一步的删除,很可能并发情况下其他线程查询数据将旧数据继续缓存到了Redis
而至于为什么要设置一个延时时间,可以设定可以接受的不一致的时间
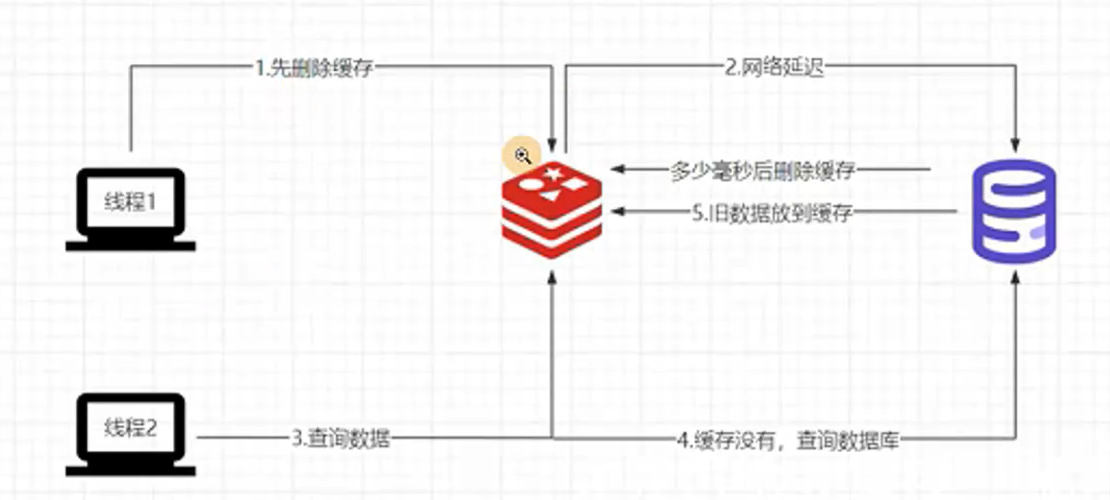
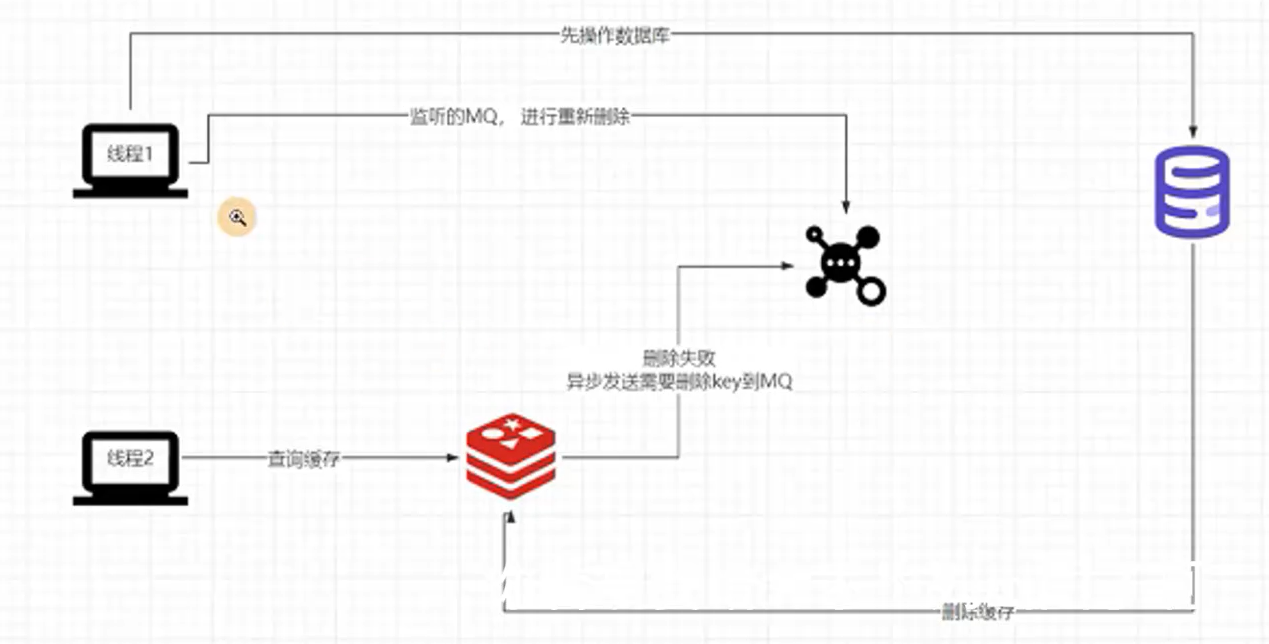
方法二:更新数据库再删缓存
引入MQ避免删除操作万一失败而导致的缓存一致性的问题(重试机制)
ThreadLocal使用原理
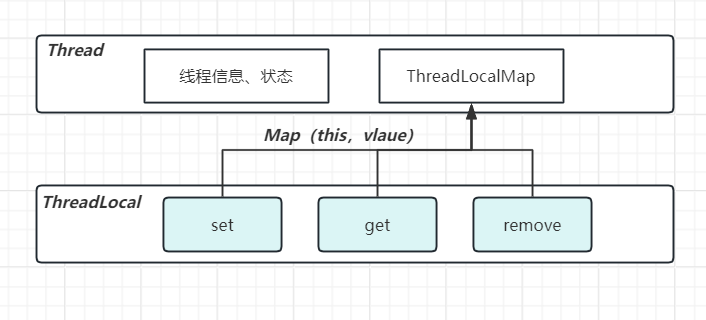
原理
- 由于是key为this所以一个ThreadLocal类只能保存一个数据,不同的ThreadLocal保存不同的信息
- Thread内部包含ThreadLocalMap,这是线程间数据隔离的关键
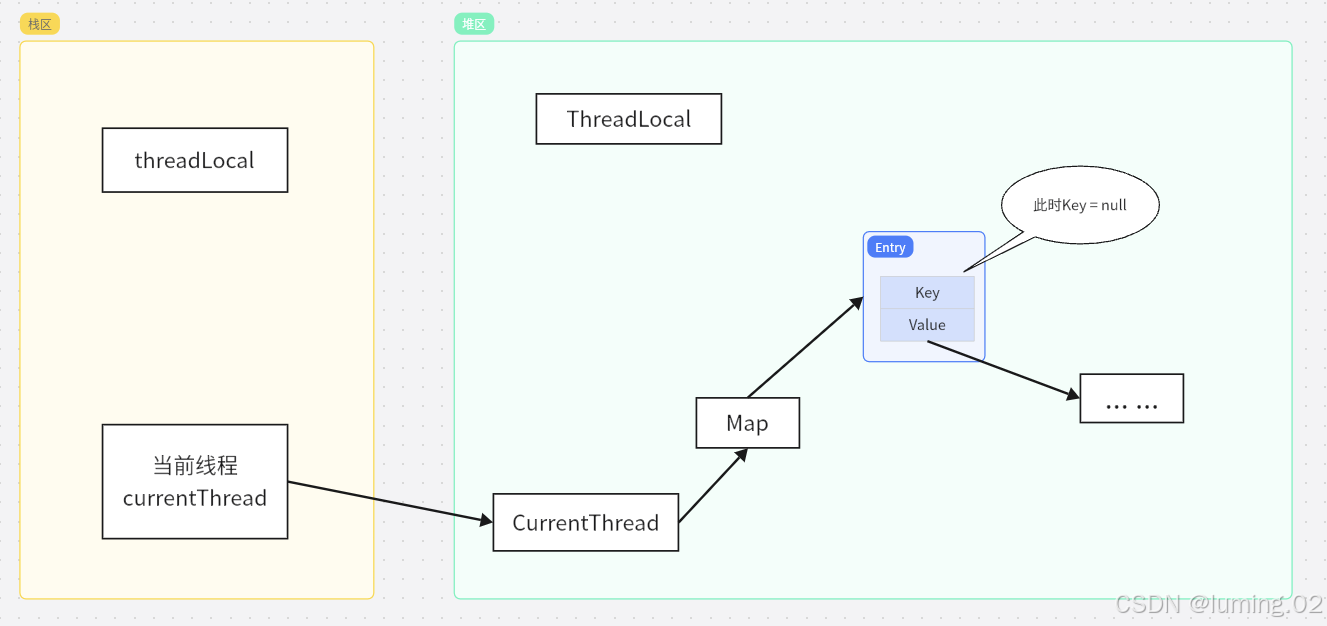
为什么ThreadLocal要使用弱引用?
确保当
ThreadLocal实例不再被外部强引用时,可以被垃圾回收器回收在这样的情况下,Entry由于仍然有Map指向它所以不会被GC回收掉,但是此时的Key又为null,所以我们无法访问到这个Value。这就导致了这个Value我们即不能访问到也不能进行回收,此时就造成了Value的内存泄漏。
使用
- 声明
UserHolder保存用户上下文信息,定义方法对ThreadLocal进行增删查
1 | public class UserHolder { |
- 拦截对应请求,通过
UserHolder方法去存取用户信息,记得最终要释放掉空间
1 | public class RefreshInterceptor implements HandlerInterceptor { |
思考
为什么ThreadLocal会有内存泄漏的风险?
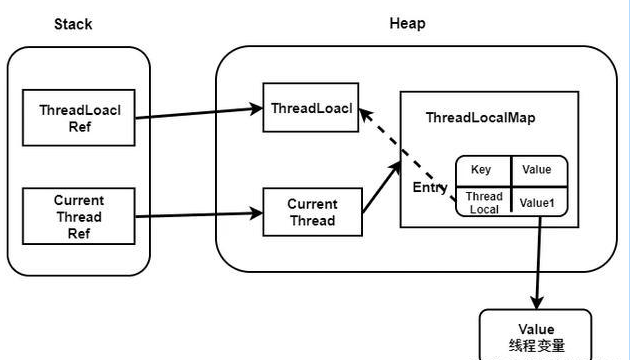
threadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal不存在外部强引用时,Key(ThreadLocal)势必会被GC回收,这样就会导致ThreadLocalMap中key为null, 而value还存在着强引用,只有thead线程退出以后,value的强引用链条才会断掉。
但如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:
Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value
永远无法回收,造成内存泄漏
为什么ThreadLocalMap中的Entry的key要声明为WeakReference?
在线程池中,一个线程会不断的从队列中拿去任务执行(不发生异常的话),这个线程是会一直存活的,换句话说他的ThreadLocalMap一直都在。
如果此时ThreadLocal作为run方法里的局部变量,且ThreadLocalMap的key不声明为弱引用(则为硬引用)。run方法跑完,threadLocal被回收,但是线程不会结束(因为是线程池的线程),ThreadLocalMap不会被回收,对应上一步的生成的Entry还是保留在ThreadLocalMap的数组中,只要Thread不死(ThreadLocalMap就还在),GC就无法回收那个Entry(key,value),然后key不为null,已经没办法判断是不是回收的了。
还是讨论ThreadLocal作为run方法里的局部变量,且ThreadLocalMap的key声明为弱引用。run方法跑完,threadLocal被回收,但是线程不会结束(因为是线程池的线程),ThreadLocalMap不会被回收,对应上一步的生成的Entry还是保留在ThreadLocalMap的数组中。等待某次GC后,Entry的key被回收,变成Entry(null,value),在remove源码中,有对key==null的Entry进行value=null的help GC的操作。在某次调用remove还能再补救一下,相比为硬引用,已经没办法补救了,已经识别不出来哪些是正在需要GC的了。
总结来说,在ThreadLocal为局部变量的时候,不声明为WeekReference,忘记remove了,然后ThreadLocal被回收后,再也没办法确认ThreadLocalMap这个认为是用完的Entry(key,value)节点是不是可以GC了。而弱引用的Entry的key,某次GC后,无用的Entry都被标记为(null, value),此时就能识别出来是泄露的内存。
1 | private void remove(ThreadLocal<?> key) { |
这样的话无论是UserContextHolder还是TenantContextHolder,只要是key被回收了指向null都会被一次性remove掉
软件开发模型
在软件工程中,开发模型是用来规划和组织软件开发过程的一组实践和技术。以下是三种常见的软件开发模型:瀑布模型、增量模型和螺旋模型。
1. 瀑布模型 (Waterfall Model)
瀑布模型是最传统的软件开发过程模型之一,它将软件开发过程划分为一系列阶段,每个阶段必须在前一个阶段完成后才能开始。这些阶段通常包括需求分析、设计、编码、测试和维护。
特点:
- 阶段性:每个阶段必须完成一定的任务,然后才能进入下一个阶段。
- 单向流动:一旦进入下一阶段,很难返回上一阶段进行修改。
- 文档化:每个阶段结束时都需要产生详细的文档。
优点:
- 结构清晰,便于管理和控制。
- 易于理解,适合小型项目或需求非常明确的项目。
缺点:
- 缺乏灵活性,一旦进入后期阶段,很难回到早期阶段进行修改。
- 不适合需求不明确或需求频繁变更的项目。
- 用户参与度较低,直到后期才能看到实际的产品。
2. 增量模型 (Incremental Model)
增量模型是瀑布模型的一种改进,它允许在开发过程中逐步交付产品的各个部分或功能模块。
特点:
- 分批次开发:将软件开发分解成一系列的增量构建,每次构建都会交付一部分功能。
- 迭代:每次增量构建都可以基于之前的反馈进行调整。
优点:
- 提高了项目的灵活性,可以在早期阶段就获得用户反馈。
- 减少了项目的总体风险,因为每次只关注一小部分功能。
- 更好地适应需求变化。
缺点:
- 管理多个增量版本可能较为复杂。
- 需要较好的计划和协调能力。
3. 螺旋模型 (Spiral Model)
螺旋模型结合了瀑布模型的阶段性和原型模型的迭代性,特别适用于大型复杂系统的开发。
特点:
- 迭代循环:每个周期包含四个主要阶段——制定计划、风险评估、工程实施、客户评估。
- 风险驱动:在每个周期开始时都要进行风险评估,以确定是否继续当前的开发路径。
- 逐步深入:随着项目的进展,逐步细化需求和解决方案。
优点:
- 能够更好地处理风险,因为每个阶段都包含了风险评估。
- 更加灵活,允许在项目早期就发现并解决问题。
- 用户参与度高,每个迭代周期结束后都会有用户评审。
缺点:
- 相对于简单的瀑布模型,管理成本更高。
- 对于小规模项目来说可能过于复杂。
- 需要有经验丰富的项目经理来指导风险评估。
每种模型都有其适用的场景,选择哪种模型取决于项目的具体情况、团队的经验以及客户的需求。在实际应用中,很多团队会根据项目的特点混合使用多种模型的特点。
分布式理论
CAP 理论(也称为布鲁尔定理)是由加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric Brewer)在2000年提出的。这一理论阐述了分布式系统设计中一致性和可用性之间的权衡。在 CAP 理论中,分布式系统的设计必须在以下三个属性中至少放弃一个:
一致性(Consistency):
- 所有节点在同一时刻看到相同的数据。
- 一次更新操作后,所有节点要么都显示新数据,要么都显示旧数据,不会出现部分节点显示旧数据,部分节点显示新数据的情况。
- 更新操作后,系统处于一致状态。
可用性(Availability):
- 每个请求(无论是否最终成功或失败)都能在合理的时间内收到响应。
- 系统能够保证非故障节点的请求都能得到响应。
- 即使有部分节点发生故障,系统仍然能够继续工作。
分区容错性(Partition tolerance):
- 网络分区(网络的一部分节点无法与其他节点通信)发生时,系统仍然能够正常运作。
- 即便网络中存在信息丢失或延迟的情况,系统也能继续运作。
CAP 理论指出,在分布式系统中,无法同时保证这三个属性。因此,设计者必须在 C、A 和 P 之间做出选择。通常情况下,系统会选择分区容错性(P),因为网络分区是一个不可避免的事实,特别是在互联网环境中。因此,设计者需要在一致性和可用性之间做出权衡。
CAP 定理的选择示例:
CA 模型:
- 当系统没有分区时,保证一致性和可用性。
- 例如:传统的事务数据库。
CP 模型:
- 在存在分区的情况下,优先保证一致性和分区容错性,可能会牺牲部分可用性。
- 例如:某些键值存储系统(如 Cassandra 在强一致模式下)。
AP 模型:
- 在存在分区的情况下,优先保证可用性和分区容错性,可能会牺牲一致性。
- 例如:大多数 NoSQL 数据库(如 Cassandra 在多数情况下)、分布式缓存系统等。
在实践中,很多分布式系统会采用混合策略,即在不同的操作或不同的数据类型上采用不同的 CAP 选择,以达到性能和一致性的平衡。此外,一些系统还会使用最终一致性(eventual consistency)的概念,即在一段时间后,所有的数据副本都会达到一致的状态,而不是立即一致。这样可以在一定程度上兼顾可用性和一致性。
UML图
https://blog.csdn.net/qq_43530773/article/details/118250152
UML(Unified Modeling Language,统一建模语言)是一种标准化的通用图形化建模语言,用于软件工程领域。它提供了一套符号体系,使得软件工程师能够以图形化的方式描述、可视化、构造以及记录软件系统的设计。UML 是由 Grady Booch、James Rumbaugh 和 Ivar Jacobson 在 20 世纪 90 年代初开发的,并在 1997 年由 Object Management Group (OMG) 标准化。
UML 的主要用途:
描述系统结构:
- 描述系统的静态结构,包括类、接口、对象以及它们之间的关系。
描述系统行为:
- 描述系统的动态行为,如交互、活动、状态转换等。
支持整个软件开发生命周期:
- 从需求分析到系统维护,UML 支持软件开发的各个阶段。
UML 图的主要类型:
类图(Class Diagrams):
- 用于描述系统的静态结构,包括类、接口、类的关系(如继承、聚合、组合等)。
对象图(Object Diagrams):
- 展示类实例(对象)及其相互关系。

组件图(Component Diagrams):
- 描述系统中的物理构件(如库、可执行文件、源代码文件等)以及它们之间的依赖关系。
部署图(Deployment Diagrams):
- 描述系统的硬件架构以及软件构件在硬件上的分布情况。
时序图(Sequence Diagrams):
- 描述对象之间如何交互以完成特定的用例或功能,强调时间顺序。
协作图(Collaboration Diagrams):
- 也称作通信图(Communication Diagrams),展示对象之间的交互,但更注重参与者之间的关系。
活动图(Activity Diagrams):
- 描述系统的活动流程,类似于流程图,但可以表示并发活动。
状态机图(State Machine Diagrams 或 Statechart Diagrams):
- 描述对象在其生命周期中的状态变化以及导致这些变化的事件。
用例图(Use Case Diagrams):
- 描述系统功能(用例)以及与系统交互的外部参与者(Actor)。
包图(Package Diagrams):
- 描述系统中逻辑模块(包)及其依赖关系。
UML 的优势:
- 统一性:提供了一套标准的符号体系,使得不同的开发人员可以共享设计信息。
- 可读性:图形化的表示方式使得设计更加直观易懂。
- 工具支持:有许多工具支持 UML,如 Eclipse 的 Papyrus、IBM Rational Rose、StarUML 等。
UML 是一个强大的工具,它帮助软件工程师在设计阶段就识别出潜在的问题,并促进团队成员之间的沟通。虽然 UML 本身并不能编写代码,但它可以帮助团队更好地理解和实现软件系统。
拦截器与过滤器
区别
在Java Web开发中,Spring MVC框架提供了两种机制来处理请求之前的逻辑或请求之后的逻辑:过滤器(Filter)和拦截器(Interceptor)。虽然它们都可以用来处理一些预处理或后处理的任务,但是它们的使用场景和实现方式有所不同。
过滤器(Filter)
过滤器是Servlet规范的一部分,因此它不仅限于Spring MVC使用。过滤器通常用于跨多个Servlet或JSP页面的功能,如编码处理、登录验证、权限检查等。
- 生命周期:过滤器的生命周期由容器管理,可以对请求进行预处理,在响应返回客户端之前进行后处理。
- 配置:过滤器是通过
web.xml文件或者使用Java配置类中的@ServletComponentScan注解来配置的。 - 执行顺序:过滤器按照在
web.xml中的声明顺序执行。 - API:使用
javax.servlet.Filter接口实现。
拦截器(Interceptor)
拦截器是Spring MVC框架特有的组件,主要用于拦截用户请求并做相应的处理。拦截器主要用于业务操作前后的处理,如记录日志、性能监控、事务处理、异常处理等。
- 生命周期:拦截器的生命周期由Spring MVC管理。
- 配置:拦截器是通过在Spring MVC的配置类中通过
addInterceptors()方法来配置的。 - 执行顺序:拦截器的执行顺序取决于你在配置类中定义的顺序。
- API:实现
org.springframework.web.servlet.HandlerInterceptor接口或继承HandlerInterceptorAdapter类。
使用场景
- 过滤器:更适合于做一些通用的功能,比如统一设置字符编码、增加响应头信息、安全控制等。(偏向于对请求的基础处理)
- 拦截器:适合于做一些业务相关的处理,比如权限校验、记录日志等。(更偏向于业务)
示例
过滤器示例
首先创建一个过滤器类:
1 | import javax.servlet.*; |
然后在web.xml中配置这个过滤器:
1 | <filter> |
拦截器示例
创建一个拦截器类:
1 | import org.springframework.web.servlet.ModelAndView; |
接着在Spring MVC配置类中注册这个拦截器:
1 | import org.springframework.context.annotation.Configuration; |
以上就是过滤器和拦截器的基本使用示例。实际应用中可以根据需求调整代码逻辑和配置。
Spring异步流式接口
ResponseBodyEmitter
使用ResponseBodyEmitter来实现下这个效果,创建 ResponseBodyEmitter 发送器对象,模拟耗时操作逐步调用 send 方法发送消息。
1 |
|
SseEmitter
SseEmitter 是 ResponseBodyEmitter 的一个子类,它同样能够实现动态内容生成,不过主要将它用在服务器向客户端推送实时数据,如实时消息推送、状态更新等场景。
StreamingResponseBody
StreamingResponseBody 与其他响应处理方式略有不同,主要用于处理大数据量或持续数据流的传输,支持将数据直接写入OutputStream。
Java的NIO详解
NIO是jdk1.4之后对BIO缺点提出的一种替换方案。N为New
适用场景:需要处理大量并发连接的场景、实时数据处理、搭建高性能服务器
BIO有什么缺点?
BIO通常是对每个连接开辟一个线程去处理事件,如果没监听到数据将会一直阻塞
- 线程的创建销毁都需要重量级的操作
- 多线程之间的并发会带来线程切换的消耗(因为要保存线程的上下文信息)
- 线程本身占用较大内存,像Java的线程的栈内存,一般至少分配
512K~1M的空间,如果系统中的线程数过千,整个JVM的内存将被耗用1G。
如何优化BIO?
现实开发中,通常用的最多的也是BIO。为了避免过高并发带来的多线程性能降低,常常会使用线程池来处理任务
但这并不能解决阻塞问题,万一连接了而不发送数据,那还是会占用没必要的线程资源!
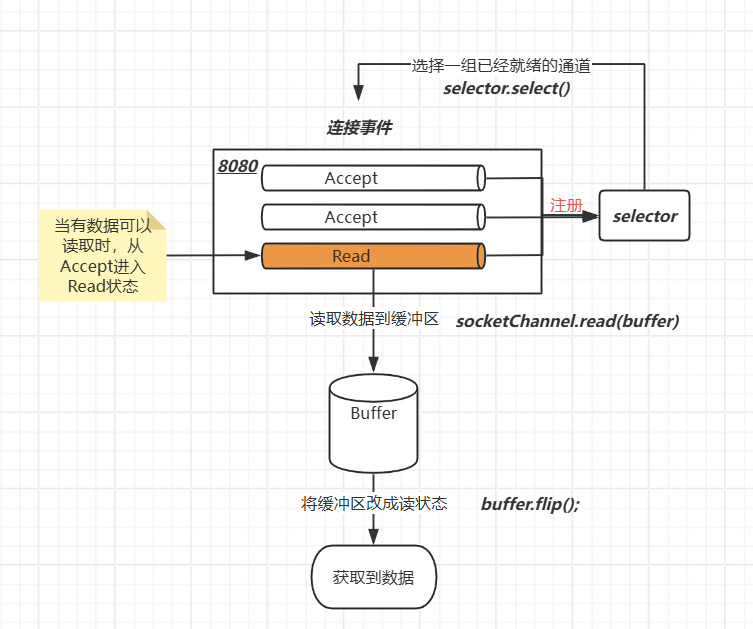
NIO的优化点
NIO结构包括:管道、选择器、缓冲区
- 管道:监听某一个端口的连接与IO(可以理解为当前端口收到了多少个连接就是多少个管道)
- 选择器:监听每个管道的事件(通过阻塞轮询定位到有数据发送的管道)
- 缓冲区:缓存读写数据
通过管道搭配选择器可以实现多路复用,一个线程监听多个连接,且这是非阻塞的,只有当有数据发送过来才会执行读取逻辑,期间可以利用该线程去做其他的事
优化点:
多路复用:减少线程消耗,最大程度利用好一个线程的资源
非阻塞:
BIO的操作是阻塞的,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。例如,我们调用一个read方法读取一个文件的内容,那么调用read的线程会被阻塞住,直到read操作完成。
NIO如何做到非阻塞的呢?当我们调用read方法时,系统底层已经把数据准备好了,应用程序只需要从通道把数据复制到Buffer(缓冲区)就行;如果没有数据,当前线程可以去干别的事情,不需要进行阻塞等待。
监听事件:
Java NIO将NIO事件进行了简化,只定义了四个事件,这四种事件用SelectionKey的四个常量来表示:
SelectionKey.OP_CONNECT
SelectionKey.OP_ACCEPT
SelectionKey.OP_READ
SelectionKey.OP_WRITE
NIO使用样例
1 | public class MultiplexingServer { |
CRM系统
面向客户,作用企业
总的来说就是通过对客户的信息管理、分析,从而制定个性化营销方案,更好的满足客户需求
客户关系管理Customer Relationship Management
客户关系管理 (CRM) 是指用于管理客户关系的全方位软件系统,而不是一个单独的解决方案。为了有效地管理、分析和改善客户关系,您需要一整套全面的云技术解决方案来帮助企业处理每一个客户交互点。
CRM 系统可收集、关联和分析所有相关客户数据,包括联系人信息、与企业销售代表的互动信息、历史购买记录、服务请求、资产和报价/提议等。然后用户可访问这些数据,并了解每个接触点的最新动态,并据此创建完整的客户档案,进而建立牢固的客户关系。
性能指标参数
吞吐量衡量单位(/s)
- 每秒查询数(
Queries Per Second,QPS):每秒查询率 - 每秒请求数(
Requests Per Second, RPS):在Web服务和API接口中,吞吐量通常表示为每秒钟能够处理的请求数。 - 每秒事务数(
Transactions Per Second, TPS):在数据库和金融系统中,吞吐量通常表示为每秒钟能够处理的事务数。 - 每秒消息数(
Messages Per Second, MPS):在消息队列和消息传递系统中,吞吐量通常表示为每秒钟能够处理的消息数。 - 每秒字节数(
Bytes Per Second, BPS):在网络传输和文件传输中,吞吐量通常表示为每秒钟能够传输的数据量
接口限流
https://blog.csdn.net/luolearn/article/details/120668323
如何设计一个高并发处理系统
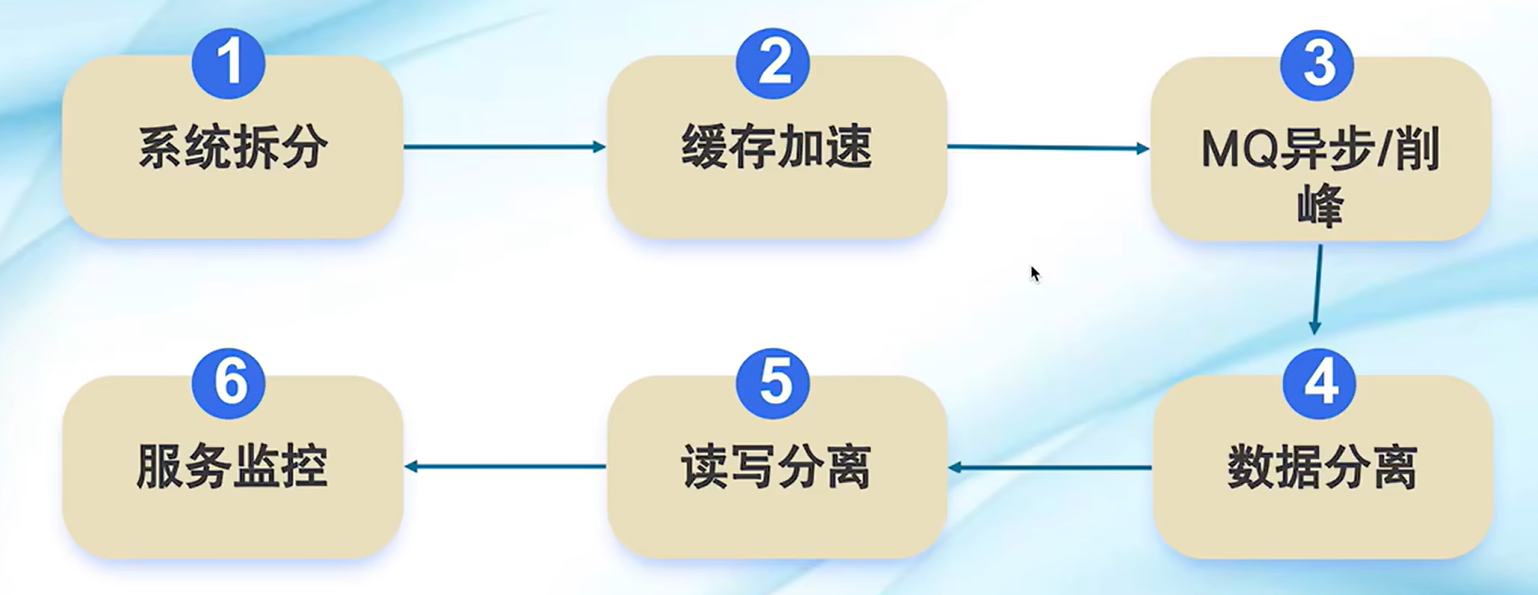
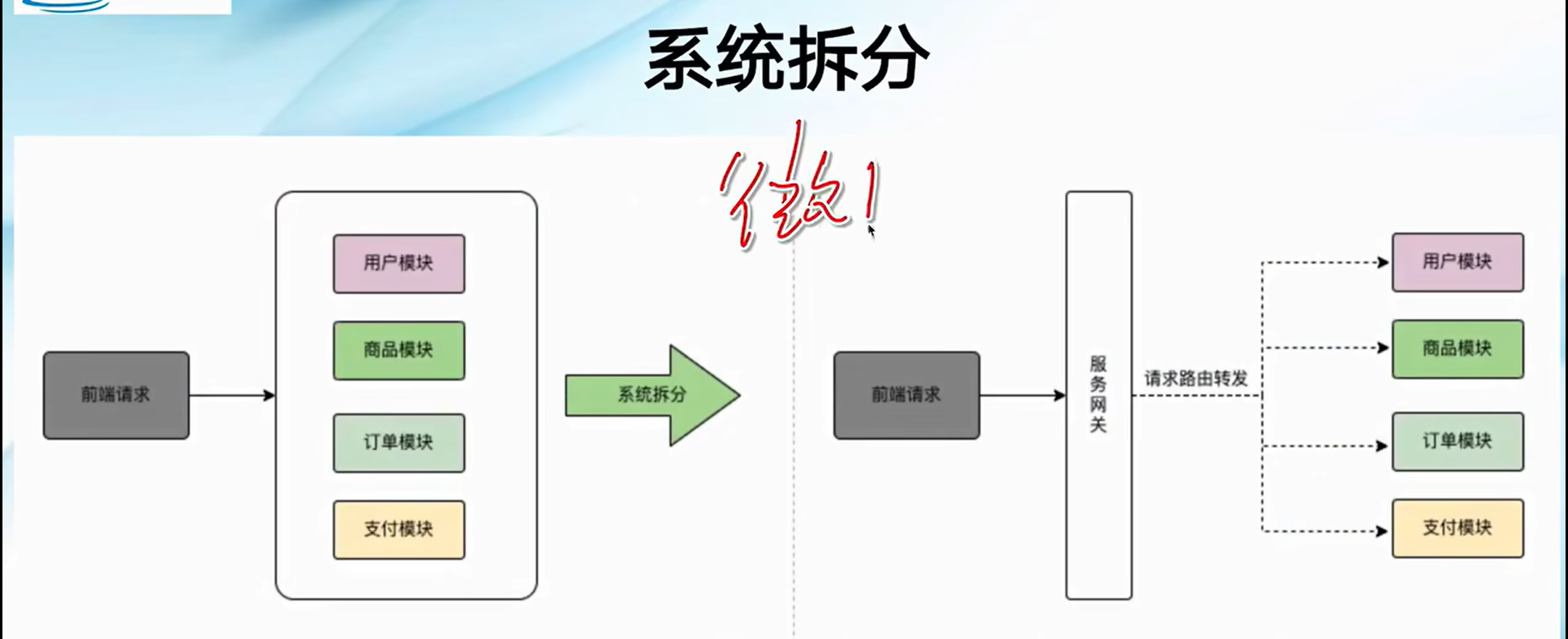
系统拆分:拆分服务,并把服务部署集群,通过负载均衡对流量进行分发
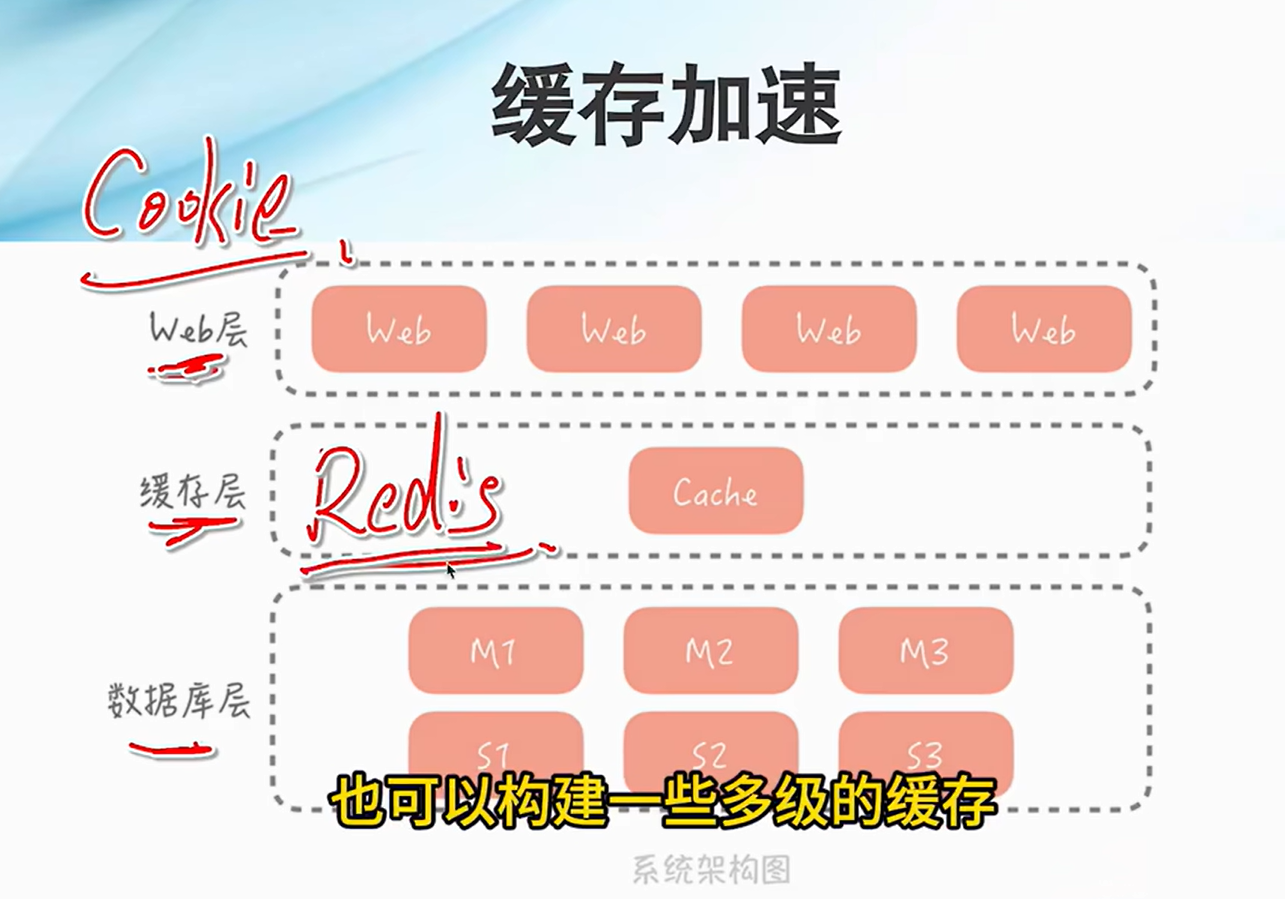
缓存加速:缓存热点数据,减少数据库的直接读取
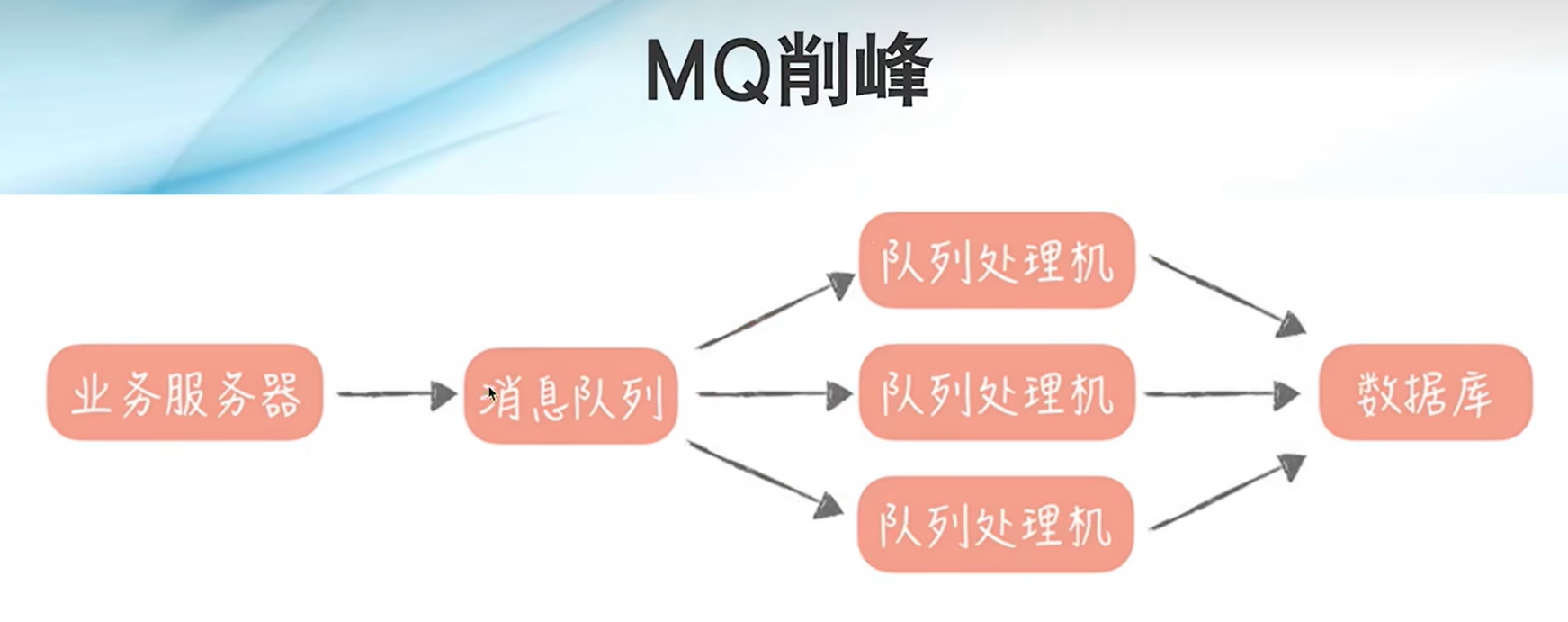
MQ异步/削峰:异步处理,加快响应时间,削峰填谷
消费者可以灵活调节,发现业务请求多了可以多添加实例,少了可以减少
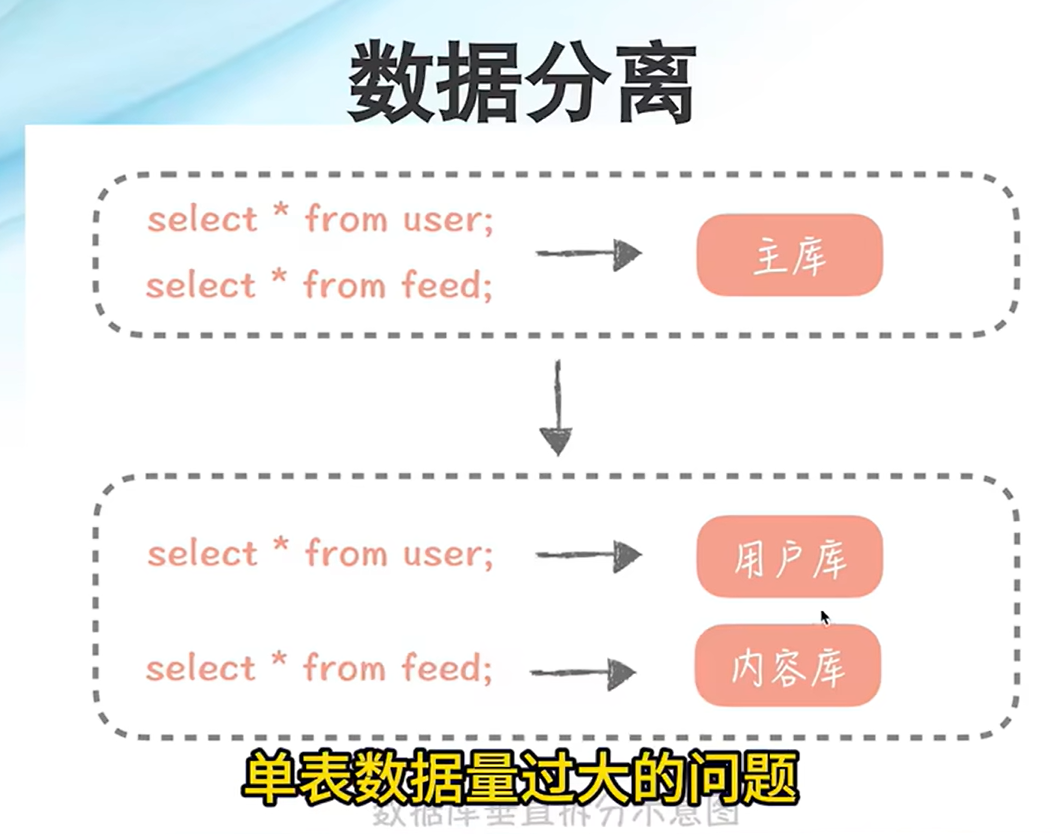
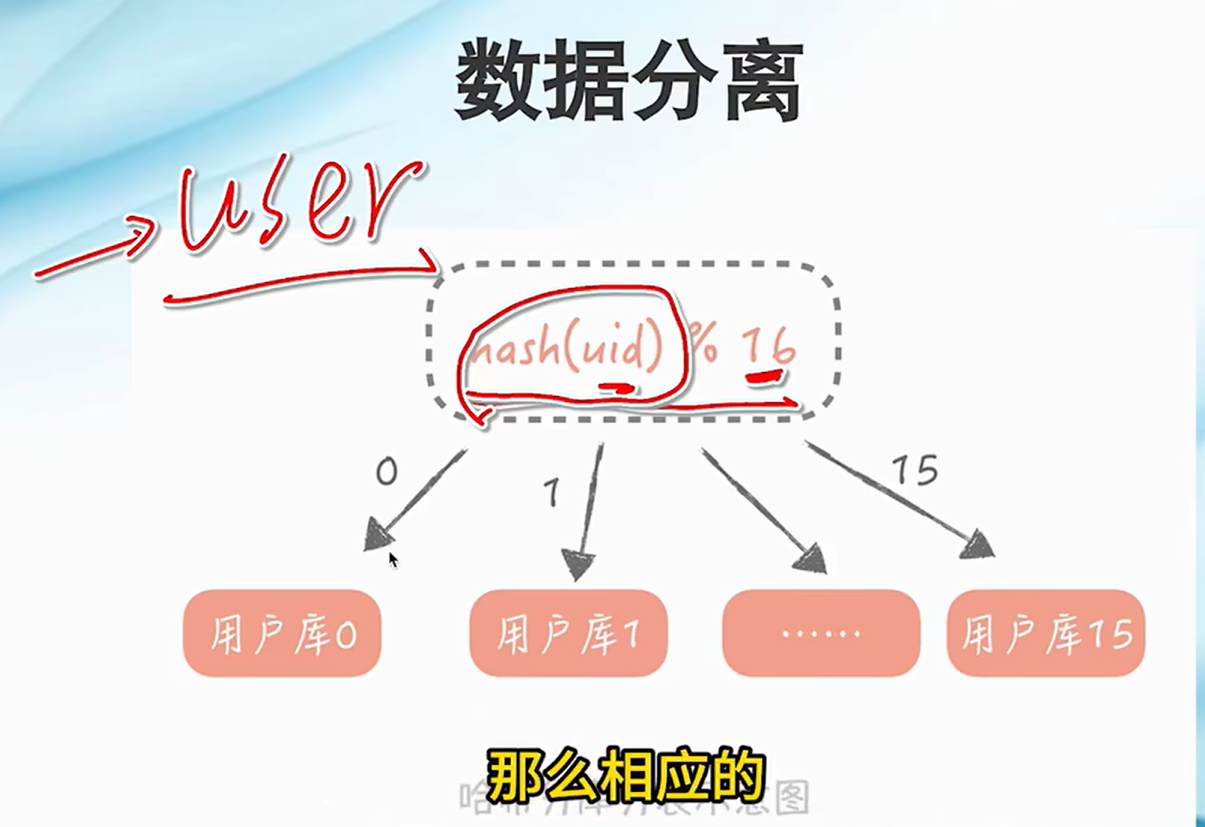
数据分离:分库分表,垂直分库减少连接数,水平分表,减少数据库大表拆成小表,数据减少加快索引查询
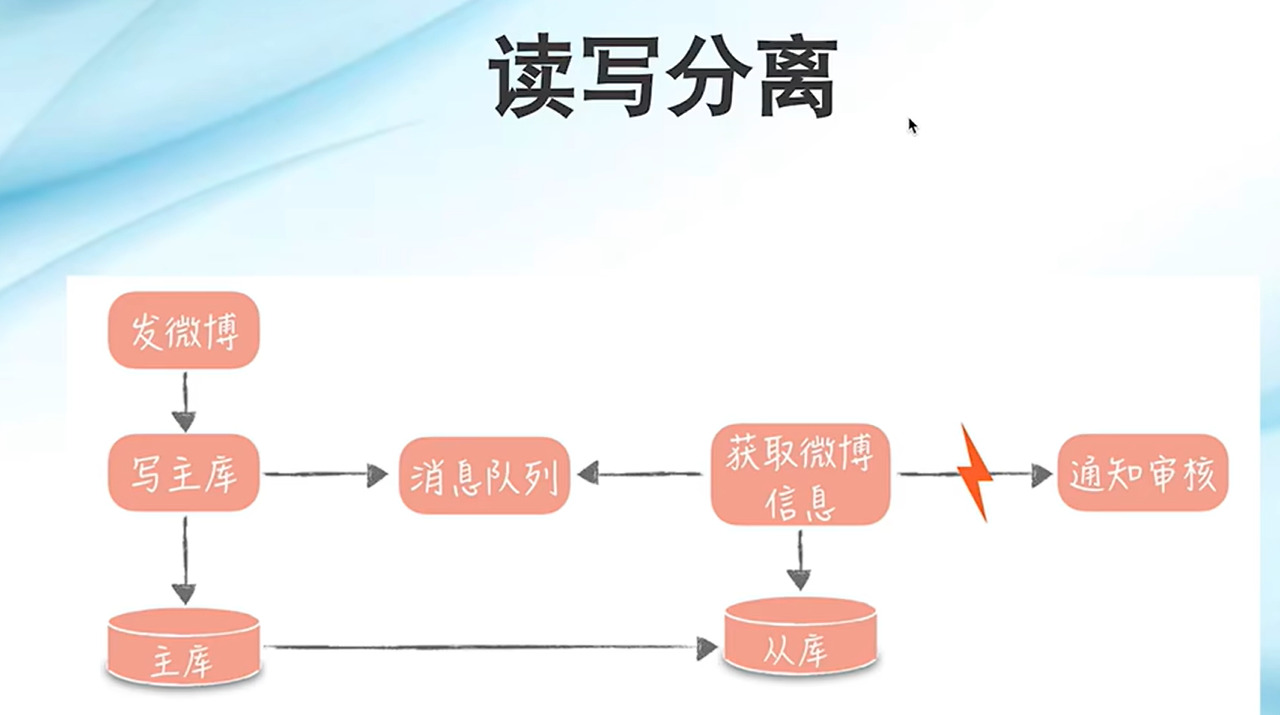
读写分离:读写互斥会降低可用性,将数据读写分离保障最终一致性的同时,加快响应时间。适合读多写少的场景
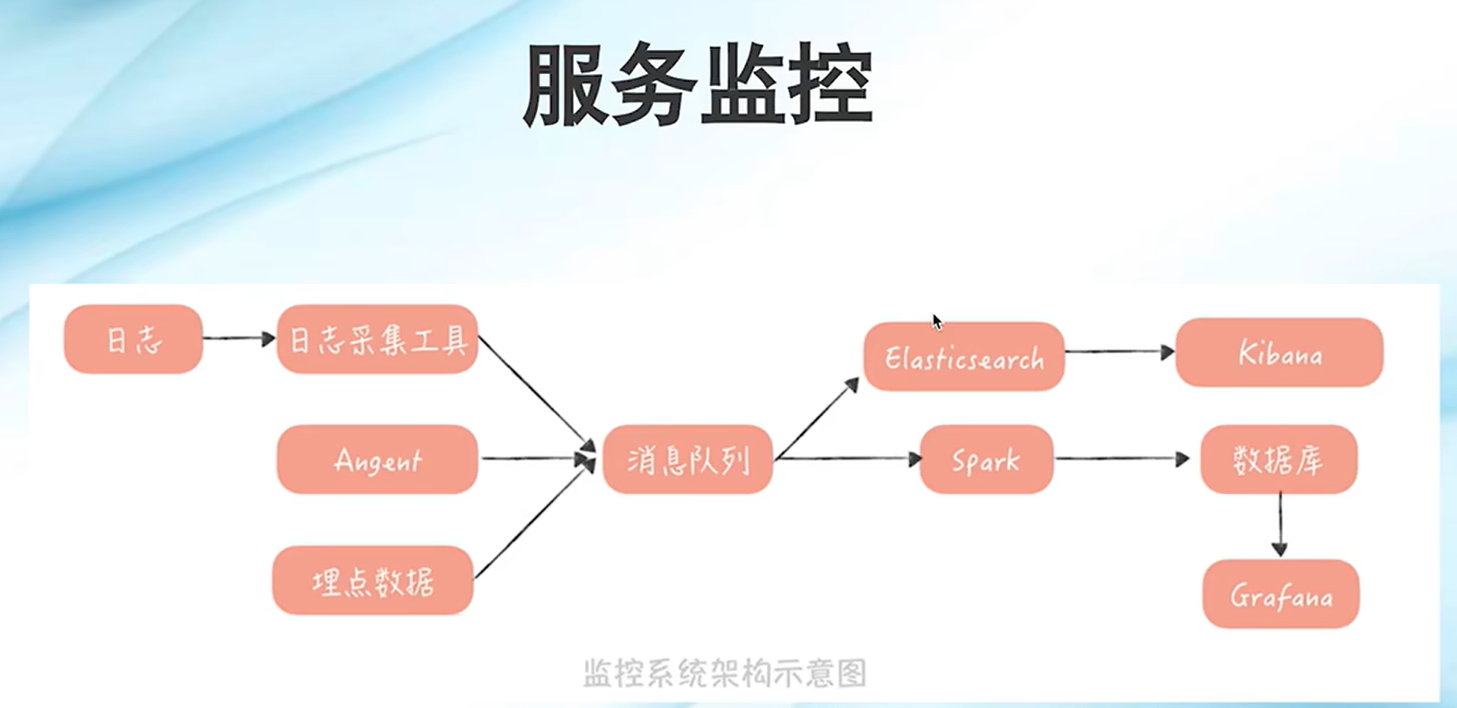
服务监控:监控服务状态,快速定位服务问题
Kafaka很适合做日志的消息队列
后台快速开发框架
若依
-
适用于国企、政府类项目,基于SpringBoot+Vue3,打造简洁高效的开发体验!国产加解密技术,国家三级等保
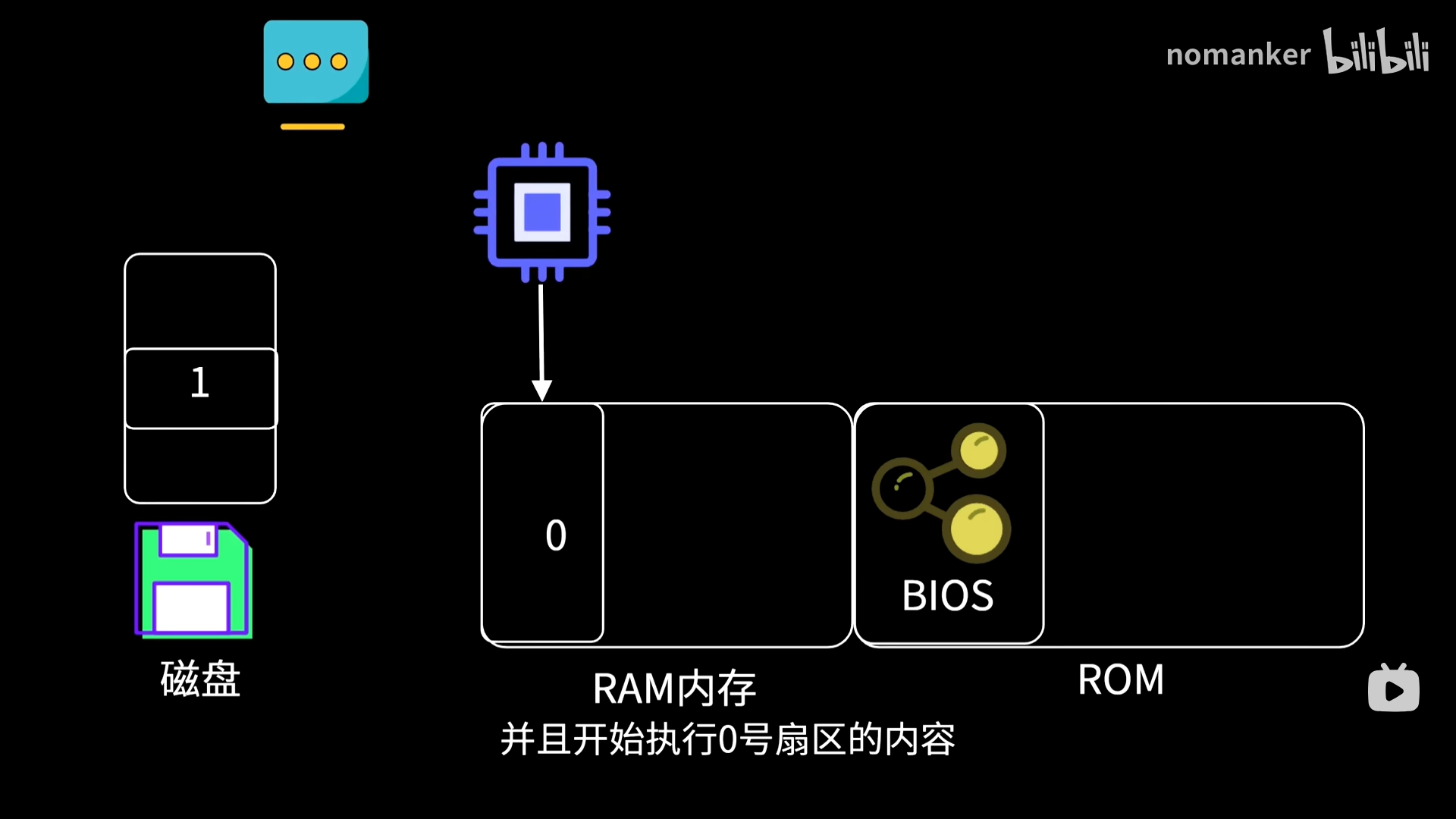
电脑如何启动

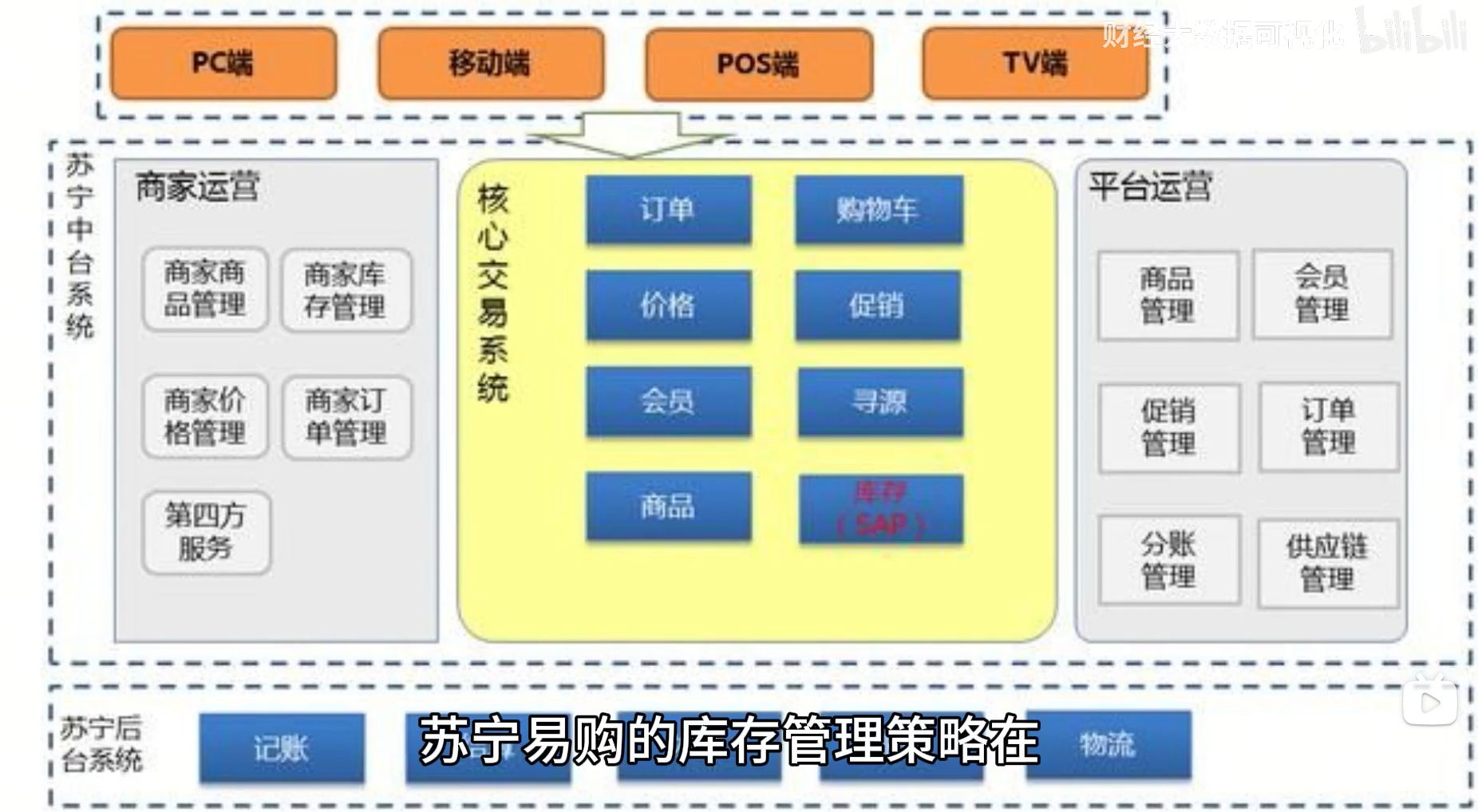
库存管理
智能化、协同化、数字化
与供应商信息共享
获取最新的产品生产计划,灵活调整补货策略
大数据分析未来需求
全国仓储网络,多仓协同
缺货可以迅速从其他地区调拨库存,同时减低库存压力
线上与线下融合,增快供货速率提升用户体验
程序员接单








