Redis学习笔记
Redis学习笔记
FANSEA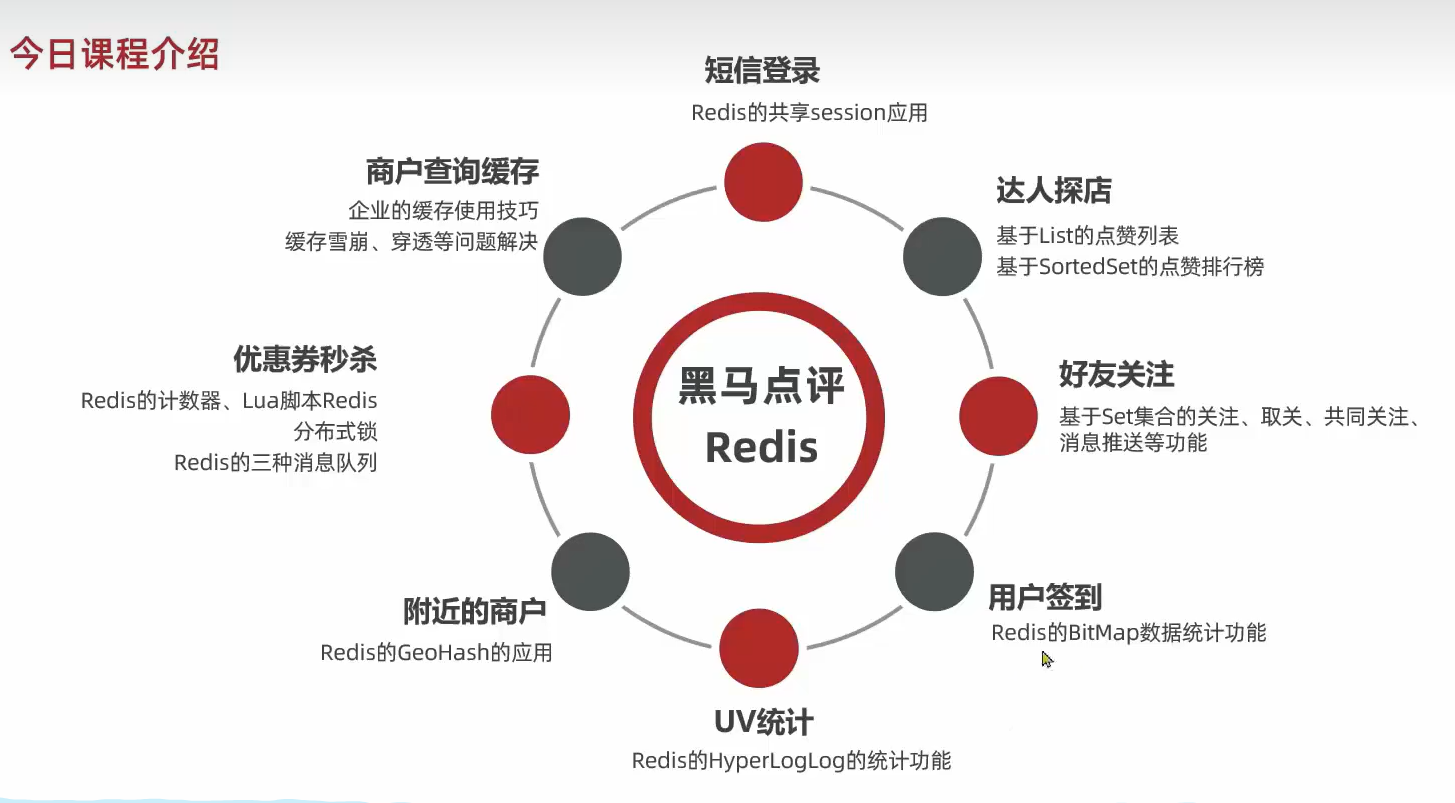
Redis学习笔记
- 缓存击穿:key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
- 缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
- 缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
redis安装教程
1.安装redis依赖环境
1 | yum install -y gcc tcl |
2.将tar.gz包放入对应目录中**/usr/local/src**,并解压
1 | tar -zxvf redis-6.2.7.tar.gz |
3.到解压目录中执行编译代码
1 | cd redis-6.2.7 |
1 | make && make install |
前台启动redis
1 | redis-server #直接启动 |
redis的配置
进入以下文件配置
1 | vim /usr/local/src/redis-6.2.7/redis.conf |
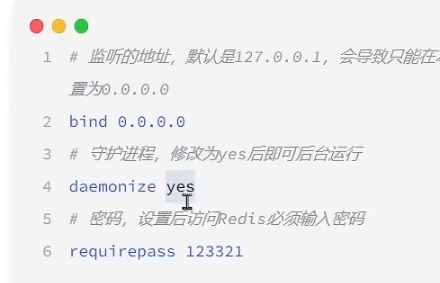
这样可以设置在后台运行,并设置访问密码
运行并指定配置文件
1 | cd /usr/local/src/redis-6.2.7 #进入启动目录 |
1 | redis-server redis.conf #启动并指定配置文件 |
redis开机自动
1.建立配置文件,将redis写入系统进程

1 | [Unit] |
如果报错一定要注意ExecStart里面地址是否错误!!!!
2.重新加载服务
1 | systemctl daemon-reload |
3.启动redis服务
1 | systemctl start redis |
4.实现开机自启动
1 | systemctl enable redis |
redis命令行客户端
1 | cd /usr/local/bin/ |
1 | redis-cil -h [120.0.0.1] -p [6379] -a [137125] |
- -h 连接的Ip地址
- -p 链接的端口号
- -a 链接的密码
1 | set name fanfan |
redis帮助文档
1 | https://redis.io/commands/ |
1 | help [指令] #展现提示 |
redis常用命令

1 | expire age 20 #20为秒 |
String常用指令

Hash常用指令

List常用指令

Set常用指令

SortedSet常用指令

redis的java客户端——jedis
点击查看: jedis官网
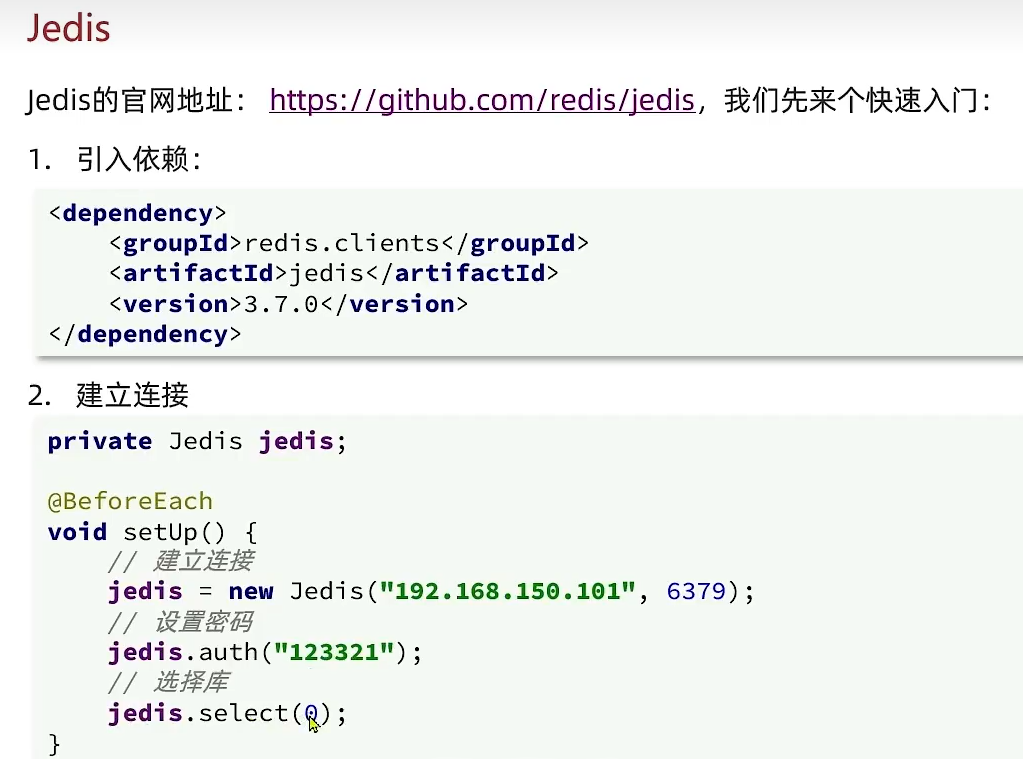

jedis依赖
1 | <dependency> |
spring -Data redis使用
1 | <!--redis的依赖默认使用自带版本不然容易报错--> |

1 | spring: |
在这里会产生一个问题:插入的key—>person在Redis中变成了\xAC\xED\x00\x05t\x00\x06person,而且数据也是\xED\x00\x05\x74\x00\x06\x66\x61\x6E\x73\x65\x61的java序列化后的格式
1 |
|
序列化问题
序列化常用工具
- json字符串转为对象
1 | Shop shop = JSONUtil.toBean(shopString, Shop.class); |
- 对象转化为json字符串
1 | String json = JSONUtil.toJsonStr(shop) |
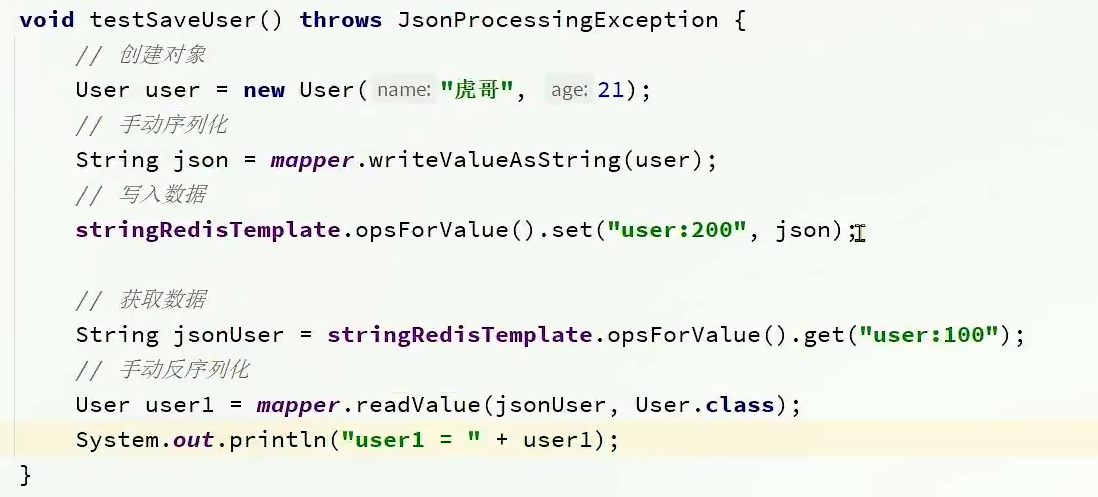
方式一,手动序列化反序列化

因为redis中默认的序列化器是jdk序列化器,所以存取数据需要自己序列化和反序列化:
使用stringRedisTemplate可以自动将序列化器转为字符串序列化器,所以需要对存数据的value(String)进行转json自己序列化处理,对于取数据则就需要对其自己反序列化
方式二,自定义序列化器
定义配置类
1 |
|
注意需要添加序列化坐标:
1 | <dependency> |
主动更新
保持数据库和缓存信息的一致性

缓存穿透
客户端发起的请求在Redis和数据库中都不存在,多线程多次请求到达数据库,有风险将数据库击溃
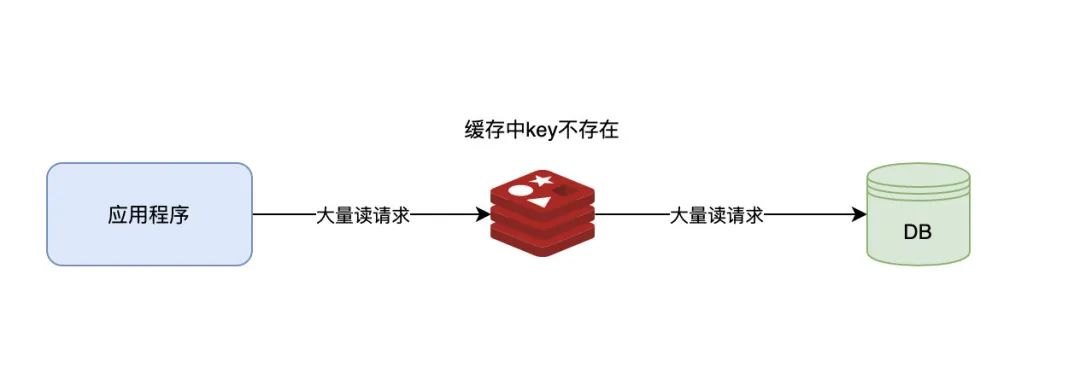

缓存穿透解决方案
- 未命中则返回数据库查询
- 如果再无数据,将key-空字符串返回保存在Redis中,并设置TTL
缓存雪崩
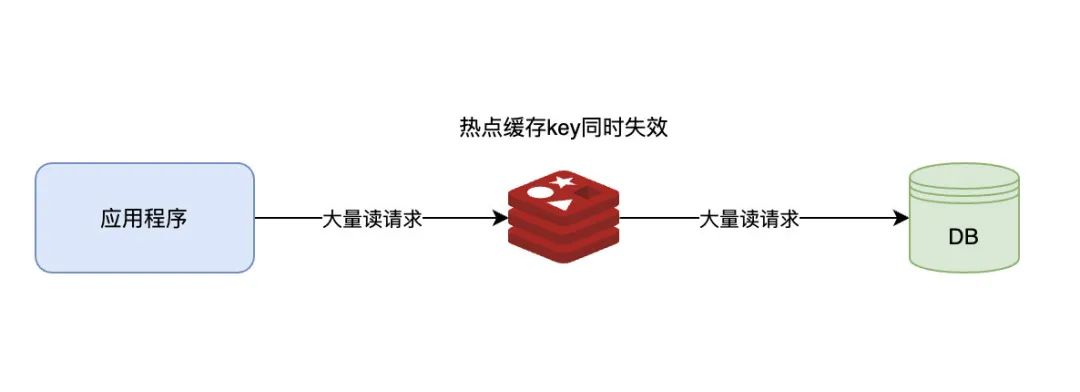
缓存中保存的数据同时失效,或者Redis服务宕机,所有请求同时打到数据库造成很大的安全隐患。

简单解决办法:给不同的key的TTL设置随机值
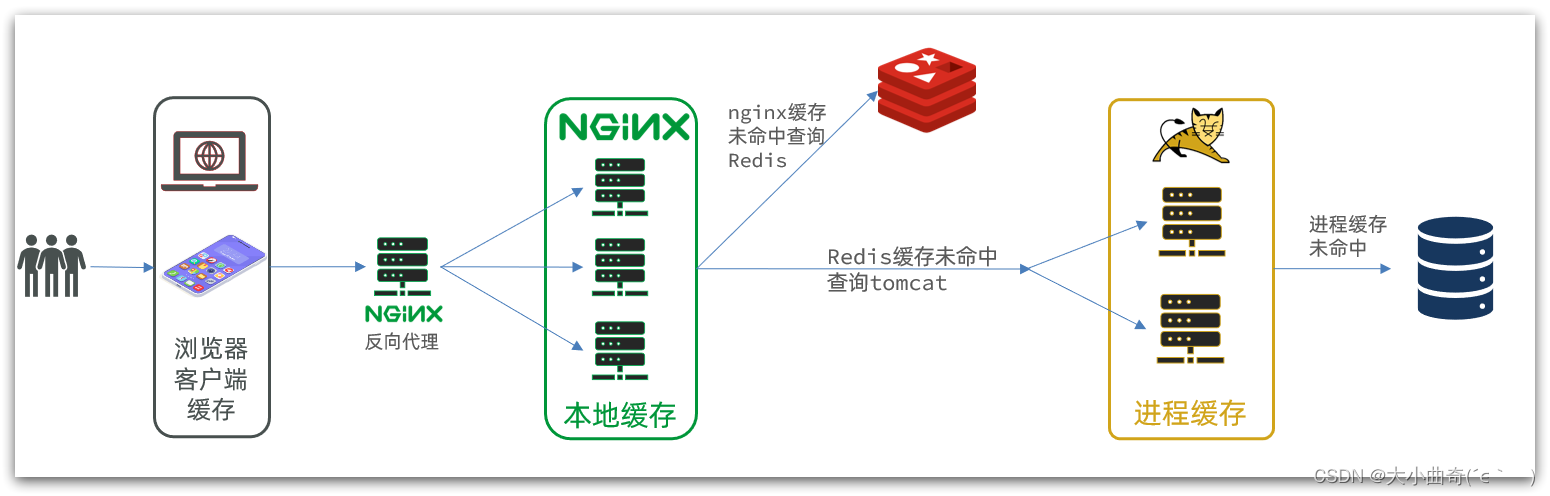
添加多级缓存
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
- 浏览器访问静态资源时,优先读取浏览器本地缓存
- 访问非静态资源(ajax查询数据)时,访问服务端
- 请求到达Nginx后,优先读取Nginx本地缓存
- 如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
- 如果Redis查询未命中,则查询Tomcat
- 请求进入Tomcat后,优先查询JVM进程缓存
- 如果JVM进程缓存未命中,则查询数据库
可见,多级缓存的关键有两个:
- 一个是在
nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询- 另一个就是在
Tomcat中实现JVM进程缓存原文链接:https://blog.csdn.net/weixin_52223770/article/details/128633716
Caffeine(JVM进程缓存)
缓存使用的基本
API:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
void testBasicOps() {
// 构建cache对象
Cache<String, String> cache = Caffeine.newBuilder().build();
// 存数据
cache.put("gf", "迪丽热巴");
// 取数据
String gf = cache.getIfPresent("gf");
System.out.println("gf = " + gf);
// 取数据,包含两个参数:
// 参数一:缓存的key
// 参数二:Lambda表达式,表达式参数就是缓存的key,方法体是查询数据库的逻辑
// 优先根据key查询JVM缓存,如果未命中,则执行参数二的Lambda表达式
String defaultGF = cache.get("defaultGF", key -> {
// 根据key去数据库查询数据
System.out.println("从数据库查询数据");
return "柳岩";
});
System.out.println("defaultGF = " + defaultGF);
}Caffeine既然是缓存的一种,肯定需要有缓存的清除策略,不然的话内存总会有耗尽的时候。
Caffeine提供了三种缓存驱逐策略:
- 基于容量:设置缓存的数量上限
2
3
4
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为 1
.build();
- 基于时间:设置缓存的有效时间
2
3
4
5
Cache<String, String> cache = Caffeine.newBuilder()
// 设置缓存有效期为 10 秒,从最后一次写入开始计时
.expireAfterWrite(Duration.ofSeconds(10))
.build();
- 基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
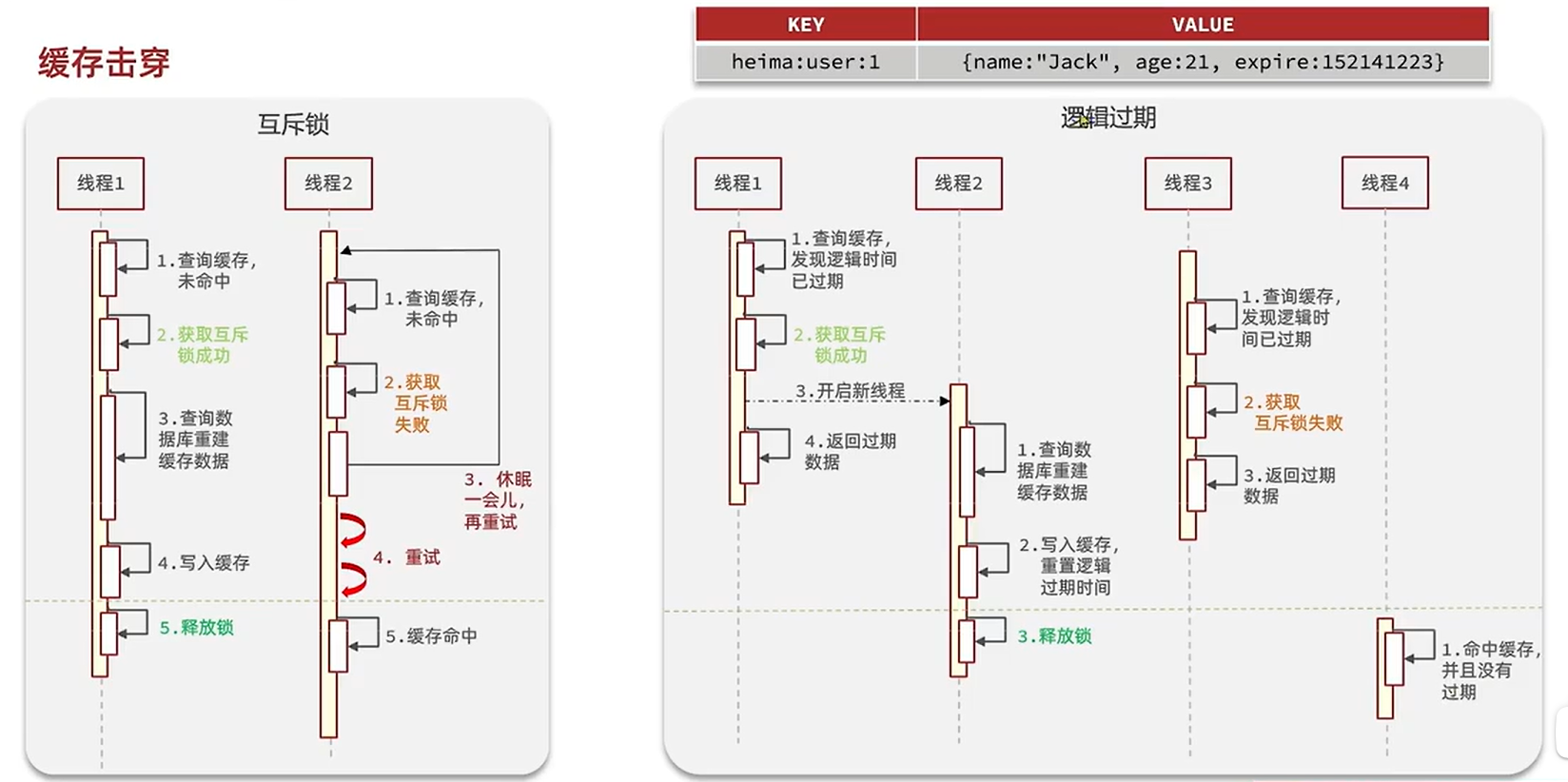
缓存击穿
- 互斥锁
- 逻辑过期:如果过期把过期数据返回,然后再尝试获取锁,后台进行缓存重建
高并发访问的key失效,多线程访问接口,会在每个线程中同时访问数据库,如果访问时间较长,数据库的工作压力就会导致服务宕机
设置互斥锁
1 | //尝试获取锁 |
互斥锁解决方案(保障一致性)
- 未查询到缓存中的数据,则先去尝试获取锁,得到锁的线程才能执行查数据库的操作。
- 其他线程未得到锁则进行休眠,休眠一段时间,重新去查询Redis缓存,如果未查到,则继续休眠
- 当得到锁的线程查询完数据库,则将数据保存在Redis缓存,释放锁,并返回数据
逻辑过期解决方案(保障程序流畅性)
此方案针对热点问题,事先需要将数据保存在Redis中,所以在程序里面默认他一直存在
- 定义RedisData类封装对象数据和过期时间
1 |
|
- 查询Redis中的数据,判断是否过期,如果未过期,直接将数据返回
1 | RedisData redisData = JSONUtil.toBean(shopString, RedisData.class); |
如果已经过期,尝试获取锁,并将过期数据返回
获取到锁则开辟一个新线程去进行缓存重建
1 | //创立线程池 |
全局id生成器
生成策略:时间戳+redis自增长数
1 | //全局ID生成器 |
理解分布式缓存
什么是分布式缓存
分布式缓存:指将应用系统和缓存组件进行分离的缓存机制,这样多个应用系统就可以共享一套缓存数据了,它的特点是共享缓存服务和可集群部署,为缓存系统提供了高可用的运行环境,以及缓存共享的程序运行机制。
本地缓存VS分布式缓存
本地缓存:是应用系统中的缓存组件,其最大的优点是应用和cache是在同一个进程内部,请求缓存非常快速,没有过多的网络开销等,在单应用不需要集群支持的场景下使用本地缓存较合适;但是,它的缺点也是应为缓存跟应用程序耦合,多个应用程序无法共享缓存数据,各应用或集群的各节点都需要维护自己的单独缓存。很显然,这是对内存是一种浪费。
分布式缓存:与应用分离的缓存组件或服务,分布式缓存系统是一个独立的缓存服务,与本地应用隔离,这使得多个应用系统之间可直接的共享缓存数据。目前分布式缓存系统已经成为微服务架构的重要组成部分,活跃在成千上万的应用服务中。但是,目前还没有一种缓存方案可以解决一切的业务场景或数据类型,我们需要根据自身的特殊场景和背景,选择最适合的缓存方案。





